AI Technology Consulting
Technical Advisory for AI Adoption, AI Development & AI Strategy
With over 10 years of experience since the dawn of AI, our team handles everything from building GPU machines to constructing and operating our own GPU data center and developing AI products end-to-end. As technical advisors, we support your AI adoption, AI development, and AI technology strategy formulation. With deep expertise in machine learning fundamentals, mathematics, and statistics—and the hands-on ability to design and implement learning algorithms from scratch—our team can provide expert technology assessment. This makes us ideal for reviewing external vendor proposals or serving as a second opinion. We provide insights for technical research, architecture design reviews, vendor selection support, and technical documentation.
LLM/Generative AI
Technical Selection & Architecture Design Advisory
Expert advice on optimal technology selection and adoption strategy.
Commercial API vs open-source LLM, RAG architecture decisions, fine-tuning feasibility— we support your technical decision-making for LLM adoption. We provide materials for informed decisions: technical research reports, architecture reviews, and vendor proposal evaluations.
Advisory Areas
Commercial API vs Local LLM
- Cost comparison & estimation
- Security requirements analysis
- Latency & throughput evaluation
- Use-case specific recommendations
Open Source LLM Selection
- Llama/Mistral/Qwen comparison
- Performance evaluation
- License & usage terms analysis
- Model size vs performance tradeoffs
Fine-tuning Strategy
- LoRA/QLoRA applicability assessment
- Continued pre-training vs fine-tuning
- Data requirements & cost estimation
- Effectiveness measurement advice
RAG Design Review
- Architecture design review
- Vector DB selection advice
- Accuracy improvement proposals
- Vendor proposal technical evaluation
Consultations We Handle
- Considering LLM adoption but lack technical decision-making expertise
- Need third-party evaluation of vendor proposals
- Want to compare costs and benefits of commercial API vs local LLM
- Need to estimate fine-tuning effectiveness and costs upfront
- Need technical briefing materials for executive presentations
- Want GPU configuration and cost estimates for LLM training/inference
Our Expertise
Operating our own GPU clusters and conducting LLM training and inference daily, we can share the following specialized knowledge:
LLM Training Realities
We explain the differences between full-scratch training, continued pre-training, and fine-tuning, along with realistic estimates for GPU requirements, timeframes, and costs.
Understanding Scaling Laws
We cover optimal balance between model size and data volume based on Chinchilla scaling laws, MoE (Mixture of Experts) architecture mechanics, and latest technical trends.
GPU Selection & Cost Estimation
We provide practical information on A100/H100/L40S characteristics comparison, NVLink importance, and cloud GPU vs on-premise TCO analysis.
Value We Provide
Vendor-Neutral Evaluation
From a position independent of any specific vendor, we advise on optimal technology selection for your needs.
Operations-Based Expertise
From our experience operating LLM products on our own GPU clusters, we provide practical advice, not just theory.
Documentation & Meeting Support
We directly support decision-making through technical research reports, comparison documents, and participation in technical review meetings.
Related Resources
We publish technical articles about LLM/Generative AI on the Qualiteg Blog.

What's Next for Claude Fable 5? A Fact-Based Look at Its Background, Costs, and Outlook
From suspension and revival to leaving the subscription tier — the confirmed pricing and cost outlook, with facts separated from speculation.

When Will a Mythos-Level Open Model Arrive?
Estimating when open models will catch up with the gated frontier, using historical open-source lag data.

API Pricing Tables for Major LLM Providers — Claude / GPT / Gemini / Grok (as of May 13, 2026)
Side-by-side per-1M-token pricing across major providers — a baseline for model selection and cost design.

Anthropic Released a Model 'Too Powerful to Release' — Mythos
What the invite-only frontier model and Project Glasswing signal: a paradigm shift toward the defender's advantage.

Japanese LLM Ranking 2026 — Benchmark Analysis Report (March 6 Edition)
A comprehensive analysis of Japanese-capable LLMs based on Nejumi Leaderboard 4 — the landscape shifted again in just three months.

Vertical Integration by AI Platformers and the Remaining Strategic Options
How AI platformers are moving into the SaaS layer, and where viable strategic positions remain.

Google GenAI SDK マルチターン画像編集の問題と対処法
Sharing the issue and solution for unstable multi-turn image editing with Gemini 3 Pro Image streaming.

LLM学習の現実:GPU選びから学習コストまで徹底解説
Explaining the reality of LLM training with specific numbers on GPU requirements, duration, and costs.

Model Context Protocol完全実装ガイド 2025
Complete guide from MCP specification evolution to latest Streamable HTTP with full source code.

日本語対応 LLMランキング2025 ~ベンチマーク分析レポート~
Comprehensive analysis of Japanese LLMs based on Nejumi Leaderboard 4 benchmark data.

【解説】Tekken トークナイザーとは何か?
Explaining Mistral's new-generation Tekken tokenizer and its differences from traditional tokenizers.

日本語対応!Mistral Small v3 解説
Explaining the Japanese-capable small model that achieves 70B+ performance with only 24B parameters.

「Open Deep Research」技術解説
Deep dive into HuggingFace's Open Deep Research architecture and implementation.

Meta社が発表した最新の大規模言語モデル、Llama 3.1シリーズの紹介
Introducing the Llama 3.1 series available in 8B, 70B, and 405B sizes.

Mistral AI社の最新LLM「Mistral NeMo 12B」を徹底解説
Explaining the Apache2-licensed 12B parameter model's features and performance.

革新的なコード生成LLM "Codestral Mamba 7B" を試してみた
Hands-on report with the new code generation LLM using Mamba architecture.

ChatStream🄬でLlama-3-Elyza-JP-8B を動かす
Testing the Japanese LLM "Llama-3-Elyza-JP" 8B version said to outperform GPT-4.
AI Agents
Advisory for Coding Agents & Business Automation Agents
Accurately assess what AI agents "can do" and their "limitations."
AI agents, especially coding agents, are evolving rapidly. However, there is a significant gap between benchmark scores and real-world performance, making accurate technical understanding essential for adoption. Based on our hands-on experience testing 20+ tools, we advise on optimal agent selection and implementation strategy for your organization.
Advisory Domains
Coding Agents
- Claude Code / Codex CLI / Aider
- GitHub Copilot Agent
- Cursor / Windsurf / Cline
- Tool comparison & selection
Tool Use & MCP Design
- External API integration design
- MCP server implementation
- File operations & DB connections
- Tool selection optimization
Multi-Agent Systems
- Inter-agent coordination design
- CrewAI/AutoGen/LangGraph
- Role assignment & workflows
- Orchestration patterns
Risk & Limitation Assessment
- Context window constraints
- Session memory loss
- Benchmark vs real-world gaps
- Cost & ROI estimation
We Help With These Challenges
- Want to adopt coding agents for the dev team but unsure which tool is best
- Need comparative evaluation of Claude Code, Cursor, Copilot, and other tools
- Want feasibility assessment and limitation analysis for AI agent business automation
- Need technical validation of AI agent proposals from vendors
- Want to understand AI agent adoption risks (context limits, accuracy constraints, etc.)
- Need training on coding agent best practices for development teams
Our Expertise
Based on our daily use of coding agents and hands-on testing of 20+ tools, we can share the following specialized insights.
Coding Agent Comparative Analysis
Practical comparison of major tools including Claude Code, Codex CLI, Aider, Cursor, Windsurf, Cline, GitHub Copilot Agent, and Amazon Q Developer. Terminal-based vs IDE-integrated trade-offs, model switching capabilities, and pricing analysis.
Understanding Structural Limitations
Context window constraints (approximately 200K tokens, depleted after ~50 Tool Uses), session memory loss issues, and accuracy degradation in long-running tasks. We explain the fundamental limitations of current agent architectures.
Benchmark vs Production Reality
There's a significant gap between SWE-bench scores and actual development performance. We explain why this gap exists and what conditions are needed to achieve production results.
Value We Provide
Practice-Based Insights
Our team uses coding agents daily and has accumulated extensive hands-on testing experience, enabling advice based on real experience.
Realistic Expectation Setting
Without being swayed by vendor or media hype, we honestly communicate what AI agents "can realistically do" and "cannot yet do."
Implementation Strategy Design
We propose realistic adoption roadmaps considering team skill levels, project characteristics, and security requirements.
Related Resources
We publish technical articles about AI agents on the Qualiteg Blog.

From a One-Sentence Request to a Finished Report — Demo Video of Our AI Agent 'Bestllam'
Watch the agent build its own task plan, run the analysis, and deliver a finished report from a single instruction.

コーディングエージェントの現状と未来への展望 【第2回】主要ツール比較と構造的課題
Detailed comparison of major tools and structural challenges including context window limitations and inter-session memory loss.

AIコーディングエージェント20選!現状と未来への展望 【第1回】全体像と基礎
A comprehensive introduction to 20+ AI coding tools, comparing commercial services and open source from a practical perspective.

ゼロトラスト時代のLLMセキュリティ完全ガイド:ガーディアンエージェントへの進化を見据えて
Explaining three transformations: Zero Trust, LLM security, and the evolution toward Guardian Agents in the AI Agent era.

Introduction to Model Context Protocol (MCP): Toward the Semantic Web
A practical introduction to MCP, the standard interface connecting AI models with external tools and data.
LLM Infrastructure
From GPU Environment Design to Distributed Inference
Infrastructure that doesn't just "work" but "scales."
Production LLM operations require proper GPU selection, memory management, inference optimization, and load balancing. We support optimal infrastructure design and construction from single GPU servers to large-scale GPU clusters, tailored to your requirements.
Technical Domains
GPU Infrastructure Design
- GPU selection (H100/A100/L40S)
- Server configuration design
- Network design (NVLink/InfiniBand)
- Storage design
Inference Optimization
- Quantization (GPTQ/AWQ/GGUF)
- vLLM/TGI utilization
- Batch processing optimization
- KV cache management
Distributed Processing
- Tensor/Pipeline parallelism
- Multi-GPU inference
- Multi-node clusters
- Load balancing design
Cloud/On-Premise
- AWS/GCP/Azure GPU utilization
- On-premise GPU server setup
- Hybrid configurations
- Cost optimization
Past Support Examples
We have extensive experience from GPU cluster construction to inference environment optimization.
Consulting Firm
- GPU server/cluster configuration estimation support
- Optimal configuration proposals based on budget and requirements
Startup
- GPU server design support for high-load environments
- Optimization balancing inference performance and cost
System Vendor
- Internal local LLM environment setup support
- Inference infrastructure construction using vLLM
Qualiteg's Strengths
In-House GPU Infrastructure Operations
We operate our own GPU cluster with NVIDIA H100/A100, and can share insights gained from real-world operations directly.
Hardware to Software
We provide integrated support from hardware-level GPU selection and server configuration to inference engine settings like vLLM and TGI.
Cost Optimization Expertise
We can propose solutions considering TCO (Total Cost of Ownership), including appropriate use of cloud GPU, on-premise GPU, and inference APIs.
Related Resources
Explore our LLM Inference Infrastructure Provisioning course on the Qualiteg Blog.

KVキャッシュのオフロード戦略とGQAの実践的理解
Strategies for offloading KV cache from GPU VRAM to CPU RAM and disk, plus GQA (Grouped-Query Attention) for dramatically reducing KV cache size.
The Reality of LLM Training: From GPU Selection to Cost Analysis
Real-world GPU requirements and costs for LLM training with examples from LLaMA 2 and DeepSeek-V3.

The Overlooked CPU Bottleneck in Multi-GPU Systems and How to Fix It with taskset
Why parallel GPU processes slow down with no GPU contention — identifying CPU-bound stages and pinning cores with taskset.

Is Your Code Running on CPU Instead of GPU? ~ONNX Runtime cuDNN Warning Fix~
How to resolve the "libcudnn.so.9" error when running GPU inference with ONNX Runtime.

Fixing 'NVIDIA GeForce RTX 50xx with CUDA capability sm_120 is not compatible' in PyTorch
The cause of the sm_120 incompatibility error on Blackwell GPUs and how to set up your PyTorch environment correctly.

Async-ifying Heavy CUDA Work in PyTorch Caused a Memory Leak — Here's the Fix
How a simple async/await refactor exhausted GPU memory, and the mechanism and solution behind it.

LLM Inference Provisioning Part 5: From GPU Node Configuration to Load Testing
Covers GPU node configuration, load testing, trade-off considerations, and real server examples.

LLM Inference Provisioning Part 4: Selecting Inference Engines
Compares inference engines like vLLM and TGI, explaining selection criteria.

LLM Inference Provisioning Part 3: Estimating Model Inference Memory Consumption
Explains GPU memory consumption factors including model footprint and KV cache.

LLM Inference Provisioning Part 2: Estimating LLM Service Request Volume
Learn how to estimate expected request volume for calculating required GPU nodes.

LLM Inference Provisioning Part 1: Basic Concepts and Inference Speed
Explains the fundamental concepts and inference speed considerations for building LLM inference infrastructure.

When Your GPU Service Hits a Segmentation Fault — A Practical Approach from Analysis to Resolution
Diagnosing a once-in-hundreds-of-restarts segfault that could take down an entire GPU service.

Optimal GPU Server Capacity Calculation: Queuing Theory and Practical Models
Learn how to calculate maximum user support capacity for GPU servers using queuing theory.

2025 NVIDIA GPU Quick Search Tool
Search and filter NVIDIA GPUs by generation and specs: Blackwell, Hopper, Ada Lovelace, and more.

[ChatStream] GPU Server Configuration for Large LLM Inference
Video explanation of GPU server/cluster configuration for large LLM inference using Llama3-70B as example.

Speculative Decoding: Accelerating LLM Inference Speed
A technique to speed up inference by using a small model to predict ahead, reducing computation load on larger models.
AI Security
Defend with AI, prepare for AI-driven threats, and protect AI itself — across all three domains
"AI and security" is no longer a single conversation.
Now that generative AI and LLMs sit at the core of business operations, the very premise of security has shifted. Where the focus used to be "how to prevent intrusion," today both attackers and defenders have started using AI, and attacks are being automated and scaled at machine speed. As Gartner highlights with AI TRiSM (AI Trust, Risk and Security Management), managing the trust, risk, and security of AI in an integrated way has become an agenda not just for IT departments, but for executive leadership.
This domain breaks down into three areas: (1) using AI to defend — "Defend with AI", (2) defending against attacks that use AI — "Defend against AI-powered attacks", and (3) protecting the AI systems themselves — "Defend AI". Depending on "who uses the AI" and "what is being protected," the necessary measures, budget, and nature of risk differ completely. We have followed the third area (Defend AI) from early on, developing our own attack-and-defense diagnostic product LLM-Audit, which tests LLM-specific attacks and defenses such as prompt injection and jailbreaks. Rather than offering generic talk or checklists, we map out "where, what, and how far to protect" together with you, based on your actual AI usage, and design realistic security that can be implemented.
The Three Domains of AI Security
(1) Defend with AI
- AI analysis of massive logs and alerts (AI-SOC)
- Threat prioritization and anomaly detection
- Guardian Agents (AI protecting AI)
- Visibility and control over "who accessed which AI with what"
(2) Defend against AI-powered attacks
- AI-generated phishing and fraudulent email content
- Deepfake voice, images, and impersonation
- Automated reconnaissance and vulnerability scanning
- Preparing for the "volume, speed, and sophistication" of attacks
(3) Defend AI — our core
- Prompt injection / Jailbreak
- RAG reference-data poisoning and context tampering
- AI agent privilege abuse and runaway behavior
- Japanese PII leakage and "invisible PII" countermeasures
- Diagnosis and defense with our own product, LLM-Audit
Three Turning Points Companies Must Prepare for Now
Of the three domains, the ones moving most rapidly right now are (2) the weaponization of AI by attackers and (3) the protection of AI systems. AI evolves fast, and "fixing it after something happens" can no longer keep up. Looking ahead to the changes coming, here are the points you should design for today.
The arrival of frontier-class open LLMs, and the need for a long-term defense plan
The most powerful AI models are approaching a level where they can discover vulnerabilities that went unnoticed for years within minutes, and automate everything from reconnaissance to building attack code. Once open-weight models (LLMs anyone can obtain) reach the same capability, that power will fall into attackers' hands as well, and the "barrier to entry" for sophisticated cyberattacks will drop sharply. What matters is not waiting to see "when it arrives," but designing in advance "what you will do when it does." Rather than one-off vulnerability assessments or ad-hoc patching, the new standard is to build AI red teaming and threat intelligence into your operations — inspecting your own organization continuously from the same AI perspective as the attacker — and to shift to a long-term defense plan that cycles through discovery, verification, prioritization, remediation, and audit.
- Operations designed on the premise of continuously updating threats
- Avoiding single-model lock-in and planning for graceful degradation
- Building an operational pipeline that can handle "a world where vulnerabilities are found in bulk"
As AI-agent-driven development becomes the norm, the attack surface changes
AI-agent-driven development and operations, exemplified by Claude Code, are rapidly becoming mainstream. AI autonomously writes code, executes commands, and communicates with the outside world — and behind that convenience lies a new attack surface that did not exist when humans reviewed every line. If the privileges granted to an agent are too broad, a single hijack can be fatal; and executing or reflecting AI output as-is can lead to unexpected destruction or data leakage. Adopting agents without designing "what, and how far, to entrust to them" turns convenience straight into risk. That is exactly why a secure AI-SDLC mindset — building security in from the start of development through operations and auditing — is indispensable.
- Indirect prompt injection via ingested code, web content, or issues (agent hijacking)
- Designing agent privileges and execution scope (least privilege, human approval boundaries)
- Supply-chain risk in AI-generated code and dependency packages
- An agent's self-report is not evidence (verification and auditing via logs)
If you run your own LLM, you must design its defense yourself
As local and open LLMs improve, more companies are standing up LLMs within their own environment (on-premises / private cloud) to keep sensitive data in-house. But "on-prem means safe" is a misconception. What you must protect is not where the model sits, but the flow of data. If you "own" your AI, you take on the responsibility of designing the defense yourself as a consistent AI governance program — applying Zero Trust principles (never trust, always verify) to LLM access, covering authentication and authorization, RAG permission design, protection of fine-tuned model weights and the inference GPU infrastructure, model poisoning countermeasures for training and inference data, and where needed, even Confidential Computing.
LLM-Audit
We develop and provide LLM-Audit, an LLM security diagnostic product. Drawing on the expertise gained from building it, we help strengthen the security of your LLM systems.
pii-fi
No attack can be blocked 100% of the time. That is precisely why it matters to establish, in advance, a state where "even if it leaks, the damage can be controlled." pii-fi is a product that detects personal information (PII) in the data you send to AI and thoroughly removes or anonymizes it. Even if information leaks by some chance, if no PII worth protecting remains in it, you can greatly contain the damage of the leak. It also handles Japanese-specific spelling variations and "invisible PII" hidden in documents, forming a defense-in-depth together with the detection-and-diagnosis of LLM-Audit.
Threats and Vulnerabilities We Primarily Address
LLMs and AI systems carry risks that did not exist in traditional software. From adversarial prompts to data leakage and supply-chain attacks, we respond practically to the threats we have faced in real development and operations.
Prompt injection
- Direct injection
- Indirect injection
- Jailbreak attacks
- System prompt leakage
Information leakage
- Training-data extraction
- PII (personal information) leakage
- Unintended output of confidential information
- Context leakage
Harmful output
- Harmful content generation
- Bias and discriminatory output
- Misinformation and hallucination
- Copyright infringement risk
System attacks
- DoS attacks (resource exhaustion)
- Model theft
- API key leakage
- Supply-chain attacks
Enterprise integration & access foundation
- Active Directory / ID & authentication integration
- Access control and privilege design
- Proxy-based control of AI usage (DLP)
- Company-wide AI governance and Shadow AI countermeasures
Japanese-specific risks
- Japanese alignment gap (attacks blocked in English slip through in Japanese)
- Japanese ambiguity (is "Misawa" a person's name or a place?)
- "Invisible PII" hidden in files (notes / hidden sheets / OCR)
- Confabulated prompt injection (verifying the AI's self-reports)
How We Work With You
Discovery
We listen to your LLM system architecture, usage scenarios, and your security concerns and challenges
Sharing the latest landscape
We share the latest attack techniques, industry trends, and best practices in AI security
LLM-Audit deployment support
We support the introduction and operation of vulnerability assessment using our in-house LLM-Audit
Qualiteg's Strengths
Expertise from building a product
We hold deep technical expertise in LLM security accumulated through developing LLM-Audit.
Keeping up with the latest attacks
We track newly discovered attack techniques every day and continuously update our assessment items.
Practical, implementable recommendations
Not just theory — we propose implementable measures grounded in actually operating LLM systems.
We defend with a "builder's" perspective
Because we handle everything in-house — from building and operating LLM inference infrastructure (GPU) to model development — we can design security grounded in implementation, not armchair theory. We walk alongside the real challenges of companies standing up their own LLMs.
AI Security on Video
We also explain our approach to AI security on the official Qualiteg YouTube channel.


Related Resources
On the Qualiteg Blog we publish technical articles on AI security (LLM attack & defense, Japanese PII protection, Zero Trust / AD integration).

Data Loss Prevention in the AI Era, Part 2 — Beyond Traditional DLP: The Fundamental Challenges AI-DLP Must Solve
Why pattern-matching DLP can't cover AI-specific leakage risks, and what AI-DLP must address instead.

How AI Is Changing Both Attack and Defense — The Security Market of 2026 and the Next Decade
We organize AI and security into three domains — "Defend with AI / Defend against AI-powered attacks / Defend AI" — and look ahead to the market and corporate readiness for the next decade.

The AI Detected, Refused, and Reflected on an Attack That Never Came
We examine, from raw logs, a "false recognition" in prompt-injection detection — the AI confabulating an attack that never happened.

Foundational Tech Behind Enterprise AI Security — Active Directory, Part 6: Common Problems and Solutions
Even with seemingly perfect settings, "it just won't work" moments are inevitable in the field. Kerberos failures, clock skew, SPN misconfigurations, DNS issues and more — all solvable with systematic troubleshooting.

What the Confusion Matrix Misses in PII Detection — Cross-Recognizer Collisions and Integration Testing
Automatic PII detection is the problem of extracting expressions from text and judging which PII type they are. We cover why unit tests alone give a false sense of safety.

Foundational Tech Behind Enterprise AI Security — Active Directory, Part 5: Browser Settings and Authentication
Following Part 4, where we covered identifying "who" accessed ChatGPT or Claude by joining the proxy server to the domain, this article explains browser settings and authentication.

Why Has Enterprise Security Become So Complex? — From the AD+Proxy Era to Modern Cloud Support
A history of enterprise security from the firewall & proxy era through SASE/SSE, and how it applies to LLM security.

Foundational Tech Behind Enterprise AI Security — Active Directory, Part 4: Proxy Servers and Integrated Windows Authentication
We explain integrating proxy servers with Kerberos authentication to monitor access to ChatGPT and Claude.

Foundational Tech Behind Enterprise AI Security — Active Directory, Part 3: Joining the Domain
The procedure for joining client PCs and servers to a domain, and the mechanics behind it.

Foundational Tech Behind Enterprise AI Security — Active Directory, Part 2: Building the Domain Environment
A detailed walkthrough of building an Active Directory domain environment for an AI security validation lab.
The Complete Guide to LLM Security in the Zero Trust Era: Toward the Evolution into Guardian Agents
We discuss three transformations: Zero Trust, LLM security, and the Guardian Agent of the AI agent era.

Foundational Tech Behind Enterprise AI Security — Active Directory, Part 1: Understanding the Basics
The fundamental concepts of Active Directory for integrating AI security solutions with the enterprise environment.

Data Loss Prevention in the AI Era, Part 1 — AI DLP and PROXY
HTTPS interception — how it works, where it breaks, and how to design AI-era data loss prevention around it.

What Is a "Guardian Agent," the New Sentinel of the AI Agent Era?
We explain Gartner's concept of the Guardian Agent and the new kind of watchdog required in the AI agent era.

Progressive PII Masking in LLM Use
How to detect PII hidden in files, and progressive masking with the LLM-Audit PII Protector.

Defending Enterprise Information in the LLM Era: The New Challenge of PII Security
A new definition of PII security for the generative AI era, and the information-defense strategy companies should adopt.

LLM-Audit — The Front Line of LLM Attack and Defense
The features of our LLM security solution "LLM-Audit" and countermeasures against LLM-specific vulnerabilities.

[LLM Security] Llama Guard: A First Step in AI Safety
The characteristics of Meta's Llama Guard and its safeguard functions for LLM input and output.
AI Avatar/AI Human
AI Character Development Combining Voice AI and Image Generation
Giving AI a "face" and "voice."
By combining LLM dialogue capabilities with speech recognition, speech synthesis, and image generation technologies, we create more natural and approachable AI interfaces. We support applications across customer support, education, entertainment, and more.
Technical Domains
Speech Recognition AI
- Whisper utilization
- Real-time speech recognition
- Speaker identification
- Noise resilience enhancement
Speech Synthesis AI
- High-quality TTS
- Emotion/intonation control
- Voice Cloning
- Multilingual support
Image Generation/Avatar
- Stable Diffusion utilization
- Character generation
- Lip sync
- Expression/motion control
Integrated Systems
- Dialogue × Voice × Video integration
- Real-time processing
- Low-latency design
- Multi-platform support
Use Cases
- 24/7 AI customer support
- AI tutors for education and training
- AI guide characters for stores and facilities
- AI characters for entertainment
- Adding face and voice to internal AI assistants
Qualiteg's Strengths
Multimodal Integration
We have experience developing systems that combine multiple AI technologies—LLM, voice, and image.
Real-Time Processing Expertise
We achieve natural conversation experiences through low-latency pipeline design for speech recognition → LLM → speech synthesis.
GPU Infrastructure Utilization
Using our in-house GPU environment, we can quickly verify model performance and select optimal combinations.
Related Resources
Explore our technical articles on AI lip-sync technology published on the Qualiteg Blog.

Generating Realistic Lip-Sync from Speech, Part 5 (2/2): Transformer Implementation and Practical Technology Choices
Why Transformers that excel in GPT aren't a drop-in for lip-sync — data, compute, and overfitting — and when to choose LSTM vs Transformer.

Generating Realistic Lip-Sync from Speech, Part 5 (1/2): Transformer Implementation and Practical Technology Choices
Transformer network design for lip-sync, its implementation challenges, and a hybrid approach combining LSTM strengths.

AI Lip-Sync Part 4: LSTM Limitations and the Transition to Transformer
Exploring LSTM model limitations and the migration to higher-precision Transformer models.

AI Lip-Sync Part 3: Learning Mouth Shape Parameters from wav2vec Features
Building models to learn mouth shape parameters from wav2vec feature vectors.

AI Lip-Sync Part 2: AI-Based Drift Correction
Technical explanation of AI-powered drift correction to automatically synchronize audio and video.

AI Lip-Sync Part 1: Phonemes and wav2vec
Introduction to phoneme concepts and wav2vec utilization—the foundation of AI lip-sync technology.
NLP/Natural Language Processing
Japanese-Specialized Advanced Text Processing & PII Detection
Embracing the depth and complexity of the Japanese language.
Global NLP tools are primarily designed for English-speaking regions and often fail to adequately handle Japanese-specific complex writing systems and context-dependent semantics. We have a team of experts who have been researching natural language processing for many years, with a wide range of technologies from morphological analysis using established libraries (MeCab/Sudachi) and NER (spaCy/GiNZA/CRF) to the latest BERT and LLM, covering different use cases, precision requirements, and speed demands. Armed with our proprietary original corpus and deep understanding of Japanese cultural context, we have achieved productization and practical implementation as a PII detection engine. We deliver truly practical NLP solutions for Japanese businesses.
The Beauty and Complexity of Japanese — And Qualiteg's Approach
Addressing the complexity of Japanese requires a well-balanced combination of rule-based heuristic methods and machine learning/deep learning approaches. Our strength lies in deeply understanding both technologies and being able to select and integrate the optimal methods for each challenge.
A Rare Multi-Layered Writing System
Hiragana, Katakana, Kanji, Roman letters, and numbers combine organically to create rich expressiveness. A single company name can be written as "株式会社国際情報技術研究所", "KJK研究所", or "ケージェーケー研究所"— this flexibility is a strength of Japanese but also makes computer processing challenging.
Context Determines Meaning
"三沢から連絡がありました" (Misawa contacted us)—Is this a person's name? Company? Place name? In Japanese, this cannot be determined without context. In English, "Mr. Misawa" (person) and "Misawa City" (place) are clearly distinguished, but Japanese requires examining broader context.
Information from the Honorific System
"山田が来ました", "山田さんが来ました", "山田様がいらっしゃいました", "山田先生がお見えになりました"— the type of honorific helps determine a person's status and required masking level. Honorifics contain multi-layered information about relationships and social standing.
Technical Domains
PII Detection
- Japanese-specialized PII detection engine
- Honorific-driven name detection
- Full support for Japanese address formats
- Phone/email pattern detection
- Context-aware high-precision detection
Named Entity Recognition (NER)
- Person/organization/location identification
- Japanese context enhancer
- spaCy/GiNZA utilization
- CRF/BiLSTM-CRF models
- Transformer-based deep learning
Morphological Analysis
- MeCab/Sudachi/Janome utilization
- Custom dictionary construction
- POS-based context judgment
- Dependency parsing
- Technical terms & neologisms support
Text Masking & De-identification
- Staged PII masking
- Safe processing before LLM use
- Multiple file formats (PDF/Excel/PPT)
- Hidden information detection
- Reversible & irreversible masking
Processing Levels: Precision vs Speed Tradeoffs
In real business scenarios, the balance between speed and precision must be flexibly adjusted based on use case, purpose, and security requirements. We propose optimal processing levels across 5 tiers based on data importance.
Ultra-Fast Scan
10K+/secHigh-speed pattern matching with regex. Instantly detects clearly formatted information like phone numbers, email addresses, and credit card numbers.
Balanced Mode
1K+/secMorphological analysis engine + rule-based inference. Understands Japanese grammar structure with POS-based context judgment.
High-Precision NER
100+/secspaCy/GiNZA + CRF/BiLSTM-CRF. Advanced named entity recognition via machine learning with flexible judgment considering entire sentence structure.
Transformer Deep Learning
100/secRoBERTa/DeBERTa Japanese models. Deep understanding of entire document context, inferring long-range dependencies and implicit information.
LLM Integration
10/secLarge Language Model integration. Human-level language understanding that comprehends abbreviations, jargon, and implicit references, proposing appropriate masking.
Consultations We Handle
- Global tools have insufficient Japanese detection accuracy, requiring additional development costs
- Need to safely remove personal information before inputting internal data to LLMs
- Want to automatically extract and mask specific information from contracts and meeting minutes
- Need high-precision Japanese text classification, summarization, and sentiment analysis
- Want to auto-classify and route customer support inquiries
- Need accurate extraction of names, organizations, and product names from internal documents
- Need PII detection that handles Japan-specific address formats (Kyoto street names, etc.)
Our Expertise
With deep expertise in Japanese NLP technology and hands-on experience developing and operating PII detection/masking products, we can share the following specialized knowledge.
Japanese-Specialized Detection Logic
Honorific-driven detection (identifying names using "様" or "さん" as cues), hierarchical pattern matching for address detection, and other techniques leveraging Japanese cultural characteristics.
Multi-Layer Filtering Technology
Morphological filtering, statistical filtering (surname/given name database matching), contextual filtering, and exclusion list application—composite approaches that improve precision.
Optimization Technology Application
Model size reduction through quantization, improved GPU efficiency via dynamic batching, lightweight model creation through knowledge distillation—achieving "high precision yet lightweight."
Qualiteg's Strengths
Years of Research & Expert Team
Our team includes specialists who have been researching NLP for many years. From morphological analysis and NER using established libraries to the latest Transformer/LLM technologies, we understand the evolution and propose optimal solutions.
Original Corpus & Productization
We possess proprietary Japanese corpora and have achieved productization as a PII detection engine. We have not just theory, but implementation capabilities proven in production environments.
Heuristics × Machine Learning Fusion
Japanese complexity requires both meticulous rule-based approaches and deep learning generalization. We deeply understand both and optimally combine them for each challenge.
Full-Stack Technology Coverage
From morphological analysis using established libraries (MeCab/Sudachi), NER (spaCy/GiNZA/CRF), to BERT/RoBERTa/DeBERTa and LLM—we provide comprehensive technologies matching your precision and speed requirements.
Deep Understanding of Japanese
We develop technology with deep understanding of Japanese cultural background, business practices, and linguistic structure. We achieve precision that sets us apart from global tools that merely "support Japanese."
Flexible Level Design
We propose optimal approaches from 5 processing levels based on use case, budget, and security requirements—preventing cost increases from excessive precision pursuit.
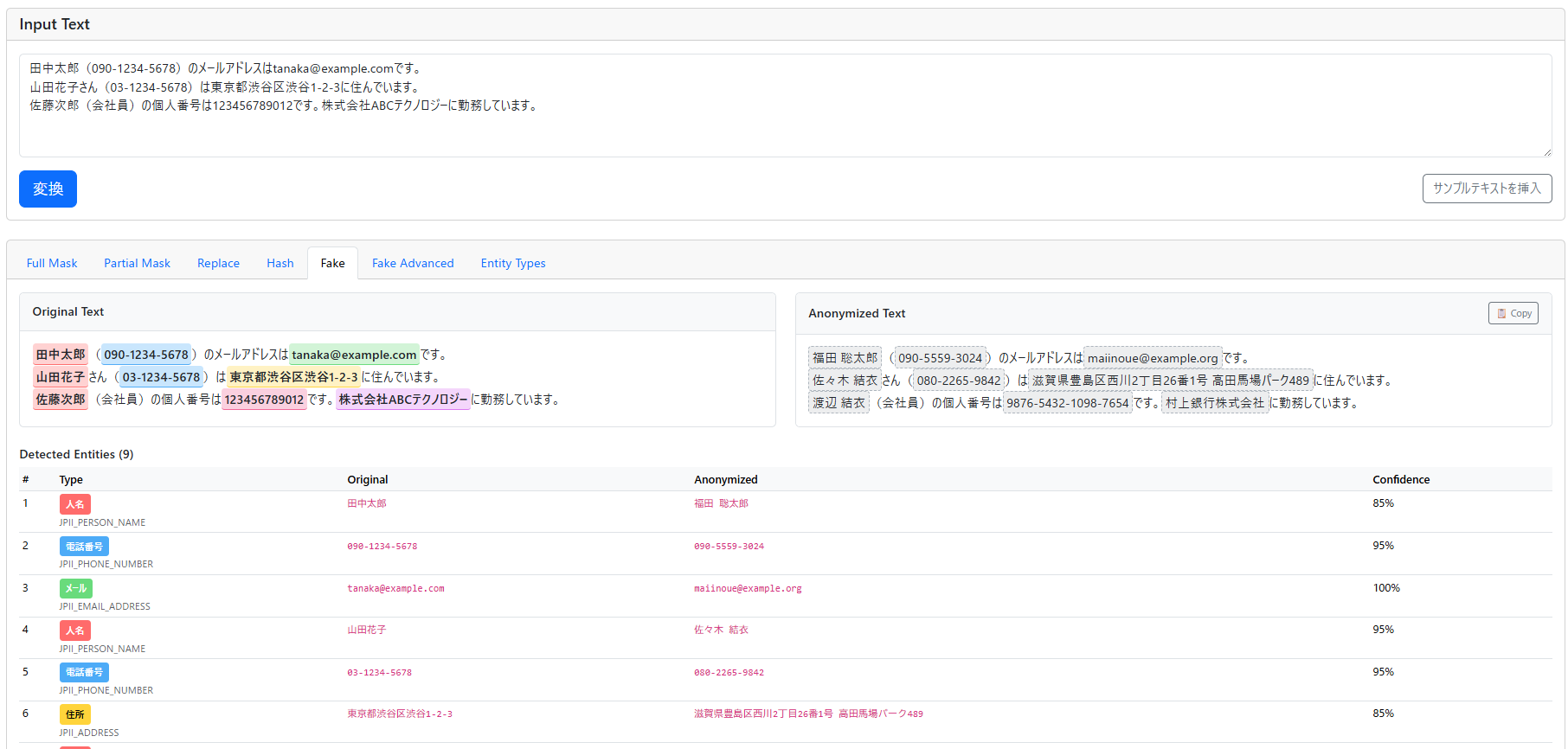
LLM-Audit
"LLM-Audit" is a comprehensive security solution for auditing enterprise LLM usage. It enables bidirectional auditing—monitoring both outbound (employee to LLM) and inbound (LLM to employee) communications. With protection against prompt injection, jailbreak attack defense, and harmful content detection/blocking, it strengthens security and compliance for enterprise AI adoption.
Qualiteg-PII-Detector
"Qualiteg-PII-Detector" is our Japanese-specialized PII detection engine integrated into LLM-Audit. It condenses years of our NLP technology expertise to enable high-precision personal information detection and masking before LLM input. It also supports detection of "hidden PII" in various file formats including PowerPoint, Excel, PDF, and images. This productized PII detection engine is proof of our Japanese NLP technical capabilities.
Related Resources

Expanding Domains Without 'Breaking' the Model — Design Notes on Continual Learning for XLM-RoBERTa
Precision collapsed from 0.83 to 0.17 after naive fine-tuning — how we designed continual learning for our PII detection engine.
PII検出の混同行列では見えないもの ― 認識器間衝突と統合テスト
Explaining the cross-recognizer collision problem in PII auto-detection and how to design integration tests to detect it.

Emoji Length Differs Between Python and JavaScript! Position-Shift Bugs Caused by Surrogate Pairs
A PII-highlighting bug traced to how Python and JavaScript count characters differently in surrogate-pair territory.

High-Precision PII Detection Technology — Embracing the Depth of Japanese Language
Coexistence of global tools and Japanese-specialized solutions. Deeply embracing Japanese unique writing systems and cultural context to deliver practical PII detection for Japanese enterprises.
AI-Driven Software Development Transformation
Integrating AI across the development lifecycle to boost productivity and quality
Integrate AI throughout the development process to achieve sustainable productivity gains.
Software development is facing a structural crisis. 23-42% of development time is wasted on technical debt, 37% of projects fail due to unclear requirements, and 87% of CTOs recognize technical debt as the biggest obstacle to innovation. This service integrates AI throughout the development lifecycle, supporting transformation across the entire process—not just point optimizations.
Structural Challenges in Software Development
The software development market is projected to reach $570 billion in 2025 and exceed $1 trillion by 2030. However, behind this rapid growth, development teams face serious challenges.
Common Challenge Patterns
Technical Debt Accumulation
- More time fixing existing code than building new features
- Accumulation of "quick fix" code becomes future burden
- Refactoring constantly postponed
- $306K annual cost per million lines of code
Requirement Ambiguity & Rework
- "This doesn't match requirements" discovered late in development
- Large number of defects found during testing phase
- Misalignment between stakeholders
- Late-stage fixes cost 10-100x more
Documentation Gaps & Knowledge Silos
- "Code exists but no specification documents"
- Only specific engineers can maintain certain code
- New members take months to onboard
- Lack of common language for international collaboration
Unclear Change Impact
- Even small changes require full system testing
- Legacy code nobody wants to touch
- Long testing periods before each release
- 15-25% of dev time spent on impact analysis
Solution Approach Through AI Integration
Traditional AI adoption has been limited to optimizing specific tasks like code completion. However, true transformation requires integrating AI across the entire development lifecycle.
Traditional Approach
- Automation of specific tasks
- Human-led throughout
- Siloed tools
- 10-20% efficiency gains
Transformed Approach
- Integration across lifecycle
- Human-AI collaboration
- Connected data & context
- 30-50%+ productivity improvement
Staged Maturity Model
Rapid transformation carries high risk—we recommend a phased approach.
AI-Assisted
Efficiency gains on individual tasks like code completion and documentation. Developers lead, AI supports.
AI-Augmented
AI utilization spanning multiple phases. AI proposes, humans decide and approve.
AI-Driven
AI supports entire lifecycle. AI drafts and executes, humans supervise and ensure quality.
AI Utilization Across Development Lifecycle Phases
Each phase of software development has unique challenges. By appropriately leveraging AI, these challenges can be addressed to improve overall project success rates. Below are specific AI applications for each phase.
Planning & Requirements Phase
The requirements definition phase determines project success or failure. Ambiguity and oversights here cause rework and budget overruns in later phases. AI helps identify contradictions and ambiguities that humans might miss, strengthening the project foundation.
Design & Architecture Phase
The design phase defines the system skeleton, requiring technology selection and architecture decisions. Documentation consumes significant time, and experienced architects' knowledge tends to become siloed. AI enables design work efficiency and knowledge sharing.
Implementation & Coding Phase
The coding phase where developers spend most of their time. AI coding assistants have seen the most adoption here, but extending beyond simple code completion to review support and refactoring suggestions yields greater benefits.
Testing & Quality Assurance Phase
The testing phase that ensures quality often becomes a bottleneck. AI support for test case design, test code implementation, and debugging enables efficient testing without compromising quality.
Deployment & Operations Phase
The phase handling production releases and stable operations. AI provides powerful support to resolve "Is this change really safe?" concerns and enable rapid incident response.
Specific Use Cases
To help visualize AI's effectiveness, here are common challenges and how AI can solve them. These are scenarios frequently raised in client consultations.
Legacy Code Visualization & Auto-Documentation
"The person who built this system has left, and nobody understands the full picture." "It took a month to explain the system to a new vendor." "The offshore team spent weeks just understanding the code"—the longer systems run, the more common these problems become. Documentation is outdated and doesn't match reality, and few people can read the code. Enormous time is spent "just understanding" each time new features or maintenance is needed.
Our AI agents analyze the entire codebase to create documentation organizing module structure, processing flows, and data flows. They systematically compile explanations like "What does this class do?" and "What's this function's role?" to quickly produce "System Overview" for new team members and "Module Reference" for maintainers. This converts siloed knowledge into accessible explicit knowledge.
Requirements-Test Traceability Automation
"Where are the test cases for this feature again?" "Requirements changed, but which tests need updating?" "Tests pass, but are we really covering these requirements?"—requirements documents and test cases are managed separately, making their relationship unclear. Result: unclear impact of requirement changes, releasing with test gap risks.
Our AI agents create traceability matrices organizing relationships between requirements and test cases. They visualize coverage by listing "Which tests cover this requirement?" and "Which requirements lack test coverage?" and suggest additional test perspectives for gaps. This transitions from "sort of testing" to evidence-based quality assurance.
Technical Debt Visualization & Executive Communication
Executives ask "Why is new feature development so slow?" Requests for "refactoring time" get blocked with "Will that increase revenue?" Development teams know technical debt is accumulating but lack words to explain it to business stakeholders. Result: debt is ignored, development velocity continues declining—a vicious cycle.
Our AI agents analyze the codebase to create technical debt status reports. They identify duplicate code, high-complexity functions, and legacy library dependencies, organizing improvement priorities. They also create executive reports translating findings into business impact like "Continued neglect will increase effort" and "This improvement will boost development speed by X%." This helps secure refactoring budgets.
Automatic Change Impact Identification
"Changed just one line, but told we need full system testing." "Nobody wants to touch this code because who knows what will break." "Two-week testing period needed before each release, slowing release cycles"—unclear change impacts cause excessive caution and slower development. Or, misjudged impact has caused production incidents.
Our AI agents analyze codebase dependencies to create documentation of inter-module call relationships. Understanding "What's impacted if this function changes?" and "Which tests to verify?" before changes enables evidence-based efficient test planning. This converts implicit knowledge from veterans' heads into explicit knowledge accessible to everyone.
Code Review Efficiency & Quality Standardization
Pull requests submitted but reviewers too busy for timely reviews. Queued reviews delay merges, disrupting development rhythm. Review quality varies by reviewer—veterans catch details while others do surface checks. Security vulnerabilities have slipped through to release.
We implement AI agent-powered review support. When pull requests are created, AI performs first-pass review to automatically detect potential bugs, security concerns, and coding standard inconsistencies. Human reviewers focus on design decisions and business logic validity that only humans can judge. This standardizes review quality while reducing wait times.
Implementation Approach
When introducing AI to development processes, attempting full-scale deployment all at once often leads to confusion and disappointing results. We recommend a phased approach. First accurately assess current state, accumulate small wins, then gradually expand scope. This approach ultimately delivers the most reliable results.
Assessment
2-4 weeksCurrent state analysis, challenge quantification, prioritization
Strategy Development
4-6 weeksTarget design, tool selection, roadmap creation
Pilot Implementation
2-4 monthsLimited scope AI implementation, effectiveness verification
Rollout & Adoption
6-12 monthsScope expansion, process adoption, continuous improvement
Expected Effects (Based on Industry Research)
Qualitative Effects
- Shift engineers to creative work: Liberation from mundane tasks
- Eliminate knowledge silos: Knowledge becomes organizational asset
- Improved developer experience: Healthy development environment not buried in technical debt
- Enhanced hiring competitiveness: Showcase cutting-edge development environment
Why Qualiteg
Large-Scale Development & International Collaboration Experience
Qualiteg members have years of experience in large enterprise system development and international collaboration projects. Teams of tens to hundreds of developers, multi-site organizations, coordination across time zones—we've experienced many complex projects. This enables us to accurately estimate AI implementation impacts and design achievable transformation plans.
Hands-On AI Agent Experience
We actively use GitHub Copilot, Cursor, Claude Code, Devin, and various code generation AI agents in our daily commercial software development—actually writing production code. We know which tools work best in which situations, where the pitfalls are, and how to operate for adoption. We provide living knowledge from our own practice, not theoretical understanding.
Practical Manufacturing & System Development Knowledge
We have particularly deep experience in embedded software development for manufacturing and enterprise system development. Quality-demanding manufacturing development processes, enterprise environments requiring legacy system integration—we've accumulated specific know-how on how to leverage AI in these contexts and what to watch out for. Not simplistic "AI will solve it" proposals, but realistic implementation plans considering on-the-ground constraints.
AI × High-Quality Software Development Balance
AI-generated code is convenient, but without quality management it risks producing security holes and unmaintainable code. Qualiteg pursues both development efficiency through AI and high-quality software. From AI-generated code review processes to test automation integration and operational rules that don't increase technical debt—we provide end-to-end support for systems that protect quality, not just efficiency.
Keys to Success
Technical
- Phased implementation: Start small and learn, don't deploy everything at once
- Tool integration: Connect siloed tools to enable data and context flow
- Quality gates: Always build in AI output verification processes
- Security consideration: Thorough security review of AI-generated code
Organizational
- Executive commitment: Transformation requires investment and time
- Frontline engagement: Both top-down and bottom-up approaches
- Role redefinition: Clarify human roles in AI collaboration
- Skill shift support: Training for evolving engineer roles
Operational
- Continuous measurement: Regular KPI monitoring
- Feedback loops: Improvements reflecting frontline input
- Knowledge accumulation: Organizational learning from success and failure patterns
Our Approach to AI Software Development
We use AI coding tools in our daily development
At Qualiteg, we routinely use various AI coding tools including Claude Code, Cursor, Windsurf, Aider, and Cline in our own product development. We use multiple tools—including internally developed ones—selected for specific purposes in actual software development.
Through this practice, we've developed an intuitive understanding of each tool's strengths and weaknesses, as well as current technical limitations.
We tackle technical challenges head-on
While AI coding tools have great potential, hands-on production use reveals challenges.
- Context overflow in long sessions
- Context not carrying over between sessions
- Gap between benchmark performance and real codebase performance
We analyze and publish these structural challenges on our technical blog, accumulating knowledge on "how to make these tools work in production."
We've witnessed software development evolution
Our team includes members with over 35 years of software development experience. We've witnessed on the ground what worked and what didn't across technology trends like SOA, microservices, and cloud.
From that perspective, the current AI-driven development support evolution feels qualitatively different from past transformations—working solutions are emerging one after another.
We share grounded, realistic insights
We don't want to overestimate or underestimate AI tool capabilities.
"Here's what works, here's what's difficult," "This tool suits this purpose," "Here's how we handle this challenge"—we aim to share these grounded insights through our consulting.
Reference Data & Sources
Claude Code Enablement
Field-tested know-how from a team that has gone all-in on "agent-first" development — from embedded software to large-scale systems
Don't let Claude Code stay merely "kind of handy." Turn it into reproducible engineering capability for your team.
Having mastered development processes at every scale — from embedded software to large-scale enterprise applications — we have committed fully to agent-first coding. We put Claude Code and other AI coding agents into real commercial development, and we have systematized what works and where the pitfalls are. This is not about superficial tool tricks; it is about rebuilding the development process itself to be agent-first — and we transplant that know-how directly into your team.
Advisory Areas
Context & Memory Design
- CLAUDE.md and context design
- Early signs of "context rot" and how to handle it
- Operating a 1M context without "using it all up"
- Memory and summarization strategy
Cross-Session Development
- Handing off tasks that don't finish in one session
- Designing for state and context carry-over
- Coping with memory loss between sessions
- Operating handover documents
Git & Change-Management Discipline
- Branching and naming conventions
- Commit-message practices
- Merge rules and review workflow
- Cleaning up the branches agents mass-produce
Quality Assurance & Safety Settings
- Automated verification via browser E2E
- Review process and quality gates for AI-generated code
- Prompt-injection countermeasures
- Permission (bypass) modes and hook configuration
Multi-Agent & Parallel Execution
- Dividing roles between a coordinator and sub-agents
- Controlling parallel tasks
- Designing per-task worker spawning
- Orchestration
Operations, Cost & People
- Monitoring rate limits and LLM cost
- Detecting runaway and zombie processes
- Turning routine work into recipes
- Growing people who can "supervise" AI
Inquiries We Handle
- We adopted Claude Code, but usage and results vary by person — we want to standardize it across the team
- We want design guidelines for CLAUDE.md, context, and memory, and to establish operations that don't "use up" the 1M context
- On long tasks the context "rots" and accuracy drops — we want to get splitting, summarization, and session design right
- We want to establish handovers for development that doesn't finish in one session
- We want to build review and quality assurance — including browser E2E — for AI-written code
- We want safe settings for prompt injection, permissions (bypass), hooks, and more
- We want to understand the causes and workarounds for real-world errors such as "The model's tool call could not be parsed" and "Usage Policy" violations
- We want best-practice training in agent-first development for our engineering team
Know-How We Can Provide (Examples)
We have rebuilt our own development to be agent-first and use Claude Code intensively in day-to-day commercial development. When issues arise, we dig down to the primary evidence (the jsonl the CLI records) to analyze them, and we have published our findings on our technical blog. From that hands-on experience, we can share know-how such as the following. These are examples only — we can support a wide range of needs depending on your challenges.
Operating Without Letting Context "Rot"
The latest models have a 1M-token context, but filling it to 100% just because the capacity exists actually lowers accuracy. Assuming it will start to "rot," when and how to split, what to summarize, and what to offload to memory — we share context design that doesn't break in real operation.
Cross-Session Development Discipline
Assuming memory is lost between sessions, how do you hand off tasks? We design discipline that works for a team — handover documents, state carry-over, branch/commit/merge practices, and cleaning up the branches agents mass-produce.
Causes and Workarounds for Real-World Issues
We identify the causes of issues that frequently occur in the field — "tool call could not be parsed" (caused by streaming with certain models plus extended thinking), false positives on "Usage Policy" violations, stream idle timeouts — from jsonl, and organize the workarounds.
Agent-Oriented Quality and Safety
We support automated verification via browser E2E, review processes and quality gates for AI-generated code, how to approach prompt injection (including the phenomenon of mistakenly "detecting" an attack that never came), and safe configuration of permissions (bypass) and hooks.
Designing Multi-Agent & Parallel Execution
The key points of dividing roles between a coordinator agent and sub-agents, controlling parallel tasks, and designing per-task worker spawning. We share practical patterns for orchestrating multiple agents without breakdowns.
Choosing Between CLI, Web, and Windows
We account for the strengths and weaknesses of Claude Code's CLI and Web versions, as well as Windows-specific pitfalls (e.g., "claude is not recognized" from a missing PATH entry), and propose the right choice for your use case and team environment.
Runaway and Cost (Rate Limit) Countermeasures
We detect and cut off unbounded billing from zombie processes or unexpected loops that "keep calling the LLM in the background" using LLM I/O monitoring. Including how to approach rate limits, we support an operating design where cost does not run away.
Guarding Against Crashes and Lost Work
A Claude Code crash can wipe out hours of investigation, discussion, and decisions in one go. With persistent session records (history plus an index), we design a mechanism that lets the next agent fully inherit the previous situation.
Growing People Who Can Properly "Supervise" AI
Rather than verifying AI output line by line, you need the ability to "supervise" from the perspectives of design, permissions, and review. Assuming "AI is confidently wrong," we grow people with the judgment for how much to delegate and where to stop.
Turning Routine Work into "Recipes"
We document steps that are used every time yet easily forgotten as "recipes," so anyone can reproduce the same quality. We turn a team's tacit knowledge into procedures as an asset and raise the reproducibility of agent operations.
Countering CLAUDE.md / Instruction Bloat
The more instructions bloat, the more accuracy drops. With separation of core and reference, internal splitting, and a "read only when needed" structure, we share a design that keeps CLAUDE.md effective without letting it grow fat.
Common Pitfalls (Examples)
- Context overflows on long sessions and accuracy drops (even with 1M, don't use 100%)
- Context isn't carried over between sessions, so you re-investigate from zero every time
- The gap between benchmark numbers and actual performance on your codebase
- "The model's tool call could not be parsed" (caused by streaming with certain models plus extended thinking)
- Legitimate operations get falsely flagged as "Usage Policy" violations and work stops
- "claude is not recognized" on Windows (missing PATH entry)
- Frequent stream idle timeouts
- Images drop out of the conversation ("an image could not be processed")
- Branches created by agents pile up and get in the way
- Zombie workers keep calling the LLM in the background and eat up the bill
- "False positives" in prompt injection (confabulating that an attack that never came was detected)
- CLAUDE.md bloats and, ironically, instructions stop working
— We have crushed these "pitfalls" hands-on in the field.
The Value We Provide
A Perspective That Has Mastered the Development Process
From decades on the front line of development — from embedded to large-scale enterprise — we support you based on the essence of the development process, not the fad of the moment.
Primary Know-How We Put Into Real Use Ourselves
We use Claude Code intensively in commercial development, still write production code daily, and dig down to jsonl to analyze and publish on issues. We hand you living know-how, not textbook knowledge.
Correcting Over-Expectations With Realistic Design
We won't make the glib claim that "adding AI makes you faster." We organize what works and the pitfalls to avoid with solid evidence, and propose realistic, decisive transformation.
Related Resources
We continually publish field know-how on Claude Code and coding agents on the Qualiteg Blog.

The Complete Guide to Claude Fable 5 — Model Specifications and Claude Code Best Practices from the Official Docs
Model specs, pricing, and the usage-credit activation deadline — the definitive guide to running Fable 5 in real work.

What Is "court"? The "XML Exposure" Phenomenon and Preventing Tool-Invocation Failures
An incident where tool-call XML-style tags get exposed on screen and are reported "complete" while never actually running. We explain detection, recovery, and prevention from raw logs.

The Complete Guide to Claude Opus 4.8 — Model Specifications and Claude Code Best Practices from the Official Docs
New effort defaults, Dynamic Workflows, and honesty improvements — what to revisit in workflows built for 4.7.
The AI Detected, Refused, and Reflected on an Attack That Never Came
A record of AI "confabulation" traced through raw logs — a study of a false positive in prompt-injection detection.

Why Legitimate Operations Get Flagged as "Usage Policy" Violations — Causes and Fixes
How false positives from the real-time cyber safeguard happen, and field workarounds.

Analyzing the Frequent "The model's tool call could not be parsed" Error — Causes and Fixes
We analyze actual session logs (jsonl) to pinpoint a streaming-induced defect and share the cause and workarounds.

Coding Agents: Present and Future (Part 3) — From "AI That Writes" to "AI That Directs"
We chart the shift to development workflows using multiple agents and the changes underway on the 2026 development floor.

Installing Claude Code on Windows via irm and Fixing 'claude is not recognized'
A known installer bug skips the PATH entry — the shortest path to a working install on Windows PowerShell.

The Complete Guide to Claude Opus 4.7 — Model Specs and Practical Claude Code Know-How
We practically summarize how to get the most out of the Claude Code CLI/Web, including effort settings and changes to tool calling.

Getting Started with Claude Code
An introductory guide for newcomers, from installing the CLI and Web versions to the basics of usage.
CONTACT
Contact Us
For questions or consultations about AI Technology Consulting,
please feel free to contact us.