AI Technology Consulting
技術顧問・アドバイザリーとして、AI導入・AI構築・AI技術戦略策定を支援
AI黎明期から10年以上の経験を持ち、GPUマシンの製作から自社GPUデータセンターの構築・運用、AIプロダクト開発まで一貫して手がけるメンバーが、技術顧問・アドバイザーとしてお客様のAI導入支援やAI構築、AI技術戦略策定を支援します。 機械学習の基礎理論から数理・統計、そしてゼロから学習アルゴリズムを設計・実装できる専門性を持ち、実際に手を動かせるメンバーが技術の目利きを行うため、外部ベンダー提案のレビューやセカンドオピニオンとしてもご活用いただけます。 技術調査、アーキテクチャ設計レビュー、ベンダー選定支援、技術資料作成など、意思決定に必要な知見を提供します。
LLM/生成AI技術
技術選定・モデル開発・アーキテクチャ設計のアドバイザリー
最適な技術選定と導入戦略を、専門家の視点でアドバイス。
商用API vs オープンソースLLM、RAG構築の方針、ファインチューニングの要否など、 LLM導入における技術的な意思決定をサポートします。 技術調査レポートの作成、アーキテクチャレビュー、ベンダー提案の評価など、お客様の判断材料をご提供します。 また、PyTorch を用いたモデル開発・評価・推論など、LLM に限らない生成AIの基盤技術(Python / PyTorch)についてもアドバイザリーを行っています。
アドバイザリー領域
商用API vs ローカルLLM
- コスト比較・試算支援
- セキュリティ要件の整理
- レイテンシ・スループット評価
- ユースケース別の推奨
オープンソースLLM選定
- Llama/Mistral/Qwen等の比較
- 日本語性能の評価
- ライセンス・利用条件の整理
- モデルサイズと性能のトレードオフ
ファインチューニング戦略
- LoRA/QLoRAの適用可否判断
- 継続事前学習 vs ファインチューニング
- 必要データ量・コストの見積もり
- 効果測定方法のアドバイス
RAG設計レビュー
- アーキテクチャ設計のレビュー
- ベクトルDB選定のアドバイス
- 精度向上のための技術提案
- ベンダー提案の技術評価
モデル開発・評価・推論(Python / PyTorch)
- PyTorch によるモデル実装・学習
- 評価・ベンチマーク設計
- 推論の高速化・安全な実行
- LLM以外の生成AI・基盤技術
こんなご相談に対応
- LLM導入を検討中だが、技術的な判断ができる人材がいない
- PyTorch でのモデル開発・評価・推論まわりを技術レビューしてほしい
- ベンダーからの提案内容を第三者視点で評価してほしい
- 商用API vs ローカルLLM、コストとメリットを比較したい
- ファインチューニングの効果やコストを事前に見積もりたい
- 経営層向けにLLM導入の技術説明資料を作成してほしい
- LLM学習・推論に必要なGPU構成とコストを試算したい
ご提供できる知見(一例)
自社でGPUクラスターを運用し、LLMの学習・推論を日常的に行っている経験から、 以下のような専門的な知見をお伝えできます。これらは一例であり、お客様の課題に応じて幅広くご支援可能です。
LLM学習のリアル
フルスクラッチ学習、継続事前学習、ファインチューニングの違いと、それぞれに必要なGPU枚数・期間・コストの現実的な見積もり方をご説明します。
スケーリング則の理解
Chinchilla則に基づくモデルサイズとデータ量の最適バランス、MoE(Mixture of Experts)アーキテクチャの仕組みなど、最新の技術動向を解説します。
GPU選定・コスト試算
A100/H100/L40S等の特性比較、NVLinkの重要性、クラウドGPU vs オンプレミスのTCO比較など、実践的な情報をご提供します。
ご提供する価値
中立的な技術評価
特定ベンダーに依存しない立場から、お客様にとって最適な技術選定をアドバイスします。
実運用に基づく知見
自社GPUクラスターでLLMプロダクトを運用している経験から、机上の空論ではない実践的なアドバイスが可能です。
資料作成・会議参加
技術調査レポート、比較資料の作成、技術レビュー会議への参加など、意思決定を直接支援します。
関連リソース
Qualiteg BlogでLLM/生成AIに関する技術解説記事を公開しています。

推論速度を向上させる Speculative Decoding(投機的デコーディング)とは
小さなモデルで先回り推論し、大きなモデルの計算負荷を下げる高速化技術を解説。

KVキャッシュのオフロード戦略とGQAの実践的理解
KVキャッシュをGPUのVRAMからCPU RAMやディスクにオフロードする戦略と、GQA(Grouped-Query Attention)によるKVキャッシュ削減技術を解説します。

公開から3日で停止──Fable 5/Mythos 5をめぐる米政府指令が示したAIの可用性リスク
公開直後に利用停止となった経緯から、AI活用の新しい可用性リスクを読み解きます。

ついに一般公開、Claude Mythos5/Fable 5 を実務視点で読み解く
同一基盤モデルにおける安全装置の差や、実務での使い分けをベンチマークとともに解説します。

Google GenAI SDK マルチターン画像編集の問題と対処法
Gemini 3 Pro Imageのストリーミングでマルチターン画像編集が不安定になる問題と解決策を共有します。

LLM学習の現実:GPU選びから学習コストまで徹底解説
LLM学習に必要なGPU枚数・期間・コストの現実を、具体的な数字と事例で解説します。

Model Context Protocol完全実装ガイド 2025
MCPの仕様変遷から最新Streamable HTTPまで、完全なソースコードと共に解説します。

日本語対応 LLMランキング2025 ~ベンチマーク分析レポート~
Nejumi Leaderboard 4のベンチマークデータに基づく日本語対応LLMの総合分析レポートです。

【解説】Tekken トークナイザーとは何か?
Mistralが採用する新世代トークナイザーの特徴と、従来のトークナイザーとの違いを解説します。

日本語対応!Mistral Small v3 解説
24Bパラメータで70B以上に匹敵する性能を実現した、日本語対応の小型モデルを解説します。

「Open Deep Research」技術解説
HuggingFace社が開発したOpen Deep Researchのアーキテクチャと実装を詳しく解説します。

Meta社が発表した最新の大規模言語モデル、Llama 3.1シリーズの紹介
8B、70B、405Bの3サイズで提供されるLlama 3.1シリーズの特徴と性能を紹介します。

Mistral AI社の最新LLM「Mistral NeMo 12B」を徹底解説
Apache2ライセンスで公開された12Bパラメータモデルの特徴と性能を解説します。

革新的なコード生成LLM "Codestral Mamba 7B" を試してみた
Mambaアーキテクチャを採用した新しいコード生成LLMの試用レポートです。

ChatStream🄬でLlama-3-Elyza-JP-8B を動かす
GPT-4を上回る性能と言われる日本語LLM「Llama-3-Elyza-JP」の8B版を試してみました。
AIエージェント
コーディングエージェント・業務自動化エージェントの導入アドバイザリー
AIエージェントの「できること」と「限界」を正しく見極める。
AIエージェント、特にコーディングエージェントは急速に進化しています。 しかし、ベンチマークの数字と実運用には大きなギャップがあり、導入には正確な技術理解が不可欠です。 20種類以上のツールを実際に検証してきた知見をもとに、貴社に最適なエージェント選定と導入戦略をアドバイスします。
アドバイザリー領域
コーディングエージェント
- Claude Code / Codex CLI / Aider
- GitHub Copilot Agent
- Cursor / Windsurf / Cline
- ツール比較・選定支援
Tool Use・MCP設計
- 外部API連携設計
- MCPサーバー構築
- ファイル操作・DB接続
- ツール選択最適化
マルチエージェント
- エージェント間協調設計
- CrewAI/AutoGen/LangGraph
- 役割分担・ワークフロー
- オーケストレーション
リスク・限界評価
- コンテキストウィンドウ制約
- セッションメモリ喪失
- ベンチマーク vs 実運用
- コスト・ROI試算
こんなご相談に対応
- コーディングエージェントを開発チームに導入したいが、どのツールが最適か分からない
- Claude Code、Cursor、Copilotなど複数のツールを比較検討したい
- AIエージェントで業務自動化が可能か、実現可能性と限界を評価してほしい
- ベンダーから提案されたAIエージェント案の技術的妥当性を評価してほしい
- AIエージェント導入のリスク(コンテキスト制限、精度の限界など)を整理してほしい
- 開発チーム向けにコーディングエージェント活用のベストプラクティス研修を実施したい
ご提供できる知見(一例)
自社でコーディングエージェントを日常的に活用し、20種類以上のツールを検証してきた経験から、 以下のような専門的な知見をお伝えできます。これらは一例であり、お客様の課題に応じて幅広くご支援可能です。
コーディングエージェント比較評価
Claude Code、Codex CLI、Aider、Cursor、Windsurf、Cline、GitHub Copilot Agent、Amazon Q Developerなど主要ツールの実践的な比較。ターミナル型 vs IDE統合型の使い分け、モデル切り替え可否、価格体系の整理など。
構造的課題の理解
コンテキストウィンドウ制限(約200Kトークン、Tool Use約50回程度で枯渇)、セッション間でのメモリ喪失問題、長時間タスクでの精度低下など、現状のエージェントが抱える根本的な制約を解説します。
ベンチマーク vs 実運用
SWE-benchなどのベンチマークスコアと、実際の開発現場での性能には大きな乖離があります。なぜ乖離が生じるのか、実運用で成果を出すための条件は何かをお伝えします。
ご提供する価値
実践に基づく知見
当社メンバーが日常的にコーディングエージェントを活用し、検証を重ねた実体験に基づくアドバイスが可能です。
過度な期待の是正
ベンダーやメディアの宣伝に惑わされず、AIエージェントの「現実的なできること」と「まだできないこと」を正直にお伝えします。
導入戦略の策定
チームのスキルレベル、プロジェクト特性、セキュリティ要件などを考慮した、現実的な導入ロードマップを提案します。
関連リソース
Qualiteg BlogでAIエージェントに関する技術解説記事を公開しています。

コーディングエージェントの現状と未来 【第3回】“書くAI”から“指揮するAI”へ
複数エージェントを使った開発ワークフローへの進化と、2026年の開発現場の変化を整理します。

AIエージェントを“事業に載せる”ために【第3回】実務で先に設計すべきこと
AI導入を止めないために、品質保証・人間レビュー・運用統制の観点で先に設計すべき点を整理します。

コーディングエージェントの現状と未来への展望 【第2回】主要ツール比較と構造的課題
主要ツールの詳細比較と、コンテキストウィンドウ制限やセッション間メモリ喪失などの構造的課題を解説します。

AIコーディングエージェント20選!現状と未来への展望 【第1回】全体像と基礎
20種類以上あるAIコーディングツールを一挙に紹介。商用サービスからオープンソースまで、現場視点で徹底比較します。

ゼロトラスト時代のLLMセキュリティ完全ガイド:ガーディアンエージェントへの進化を見据えて
ゼロトラストとLLMセキュリティ、AIエージェント時代のガーディアンエージェントという3つの変革について解説します。
LLMインフラ・基盤技術
GPU環境・インフラ設計のアドバイザリー
GPU環境の選定・設計を、運用経験に基づきアドバイス。
クラウドGPU vs オンプレミス、GPU機種の選定、推論エンジンの比較など、 LLMインフラに関する技術的な意思決定をサポートします。 自社でGPUクラスターを運用している経験を活かし、実践的なアドバイスをご提供します。
技術領域
GPUインフラ設計
- GPU選定(H100/A100/L40S等)
- サーバー構成設計
- ネットワーク設計(NVLink/InfiniBand)
- ストレージ設計
推論最適化
- 量子化(GPTQ/AWQ/GGUF)
- vLLM/TGI活用
- バッチ処理最適化
- KVキャッシュ管理
分散処理
- テンソル並列/パイプライン並列
- マルチGPU推論
- マルチノードクラスター
- 負荷分散設計
クラウド/オンプレ
- AWS/GCP/Azure GPU活用
- オンプレGPUサーバー構築
- ハイブリッド構成
- コスト最適化
研究用GPUワークステーション調達
- RTX系/プロ向けGPUの選定
- 自作 vs ベンダー調達の比較
- 研究・PoC向けの構成設計
- 電源・冷却・拡張性・予算最適化
GPU環境構築・互換性対応
- CUDA / cuDNN / ドライバ構成
- PyTorch × CUDA × GPU世代の互換性
- 最新GPU(RTX 50 / Blackwell sm_120)対応
- 環境トラブルの切り分け・解決
こんなご相談に対応
- GPU環境の構成・見積もりについてアドバイスがほしい
- 最新GPU(RTX 5090等)やCUDA・ドライバ周りの環境構築・トラブルで止まっている
- クラウドGPU vs オンプレミス、どちらが適切か判断したい
- ベンダーからのGPUサーバー提案を技術評価してほしい
- 推論エンジン(vLLM/TGI等)の比較情報がほしい
- 研究・PoC 用の GPU ワークステーションを選定・調達したい
- GPUインフラのコスト試算・比較資料を作成したい
アドバイザリー実績例
技術顧問・アドバイザーとして、GPU環境に関する意思決定を支援してきました。
コンサルティング会社
- GPUサーバー構成の見積もり・比較資料作成
- 予算と要件に応じた最適構成のアドバイス
スタートアップ
- GPUサーバー選定に関する技術アドバイス
- 推論性能とコストの比較検討支援
システムベンダー
- ローカルLLM環境の設計レビュー
- 推論エンジン選定のアドバイス
ご提供する価値
運用経験に基づくアドバイス
NVIDIA H100/A100を搭載した自社GPUクラスターの運用経験から、実践的なアドバイスが可能です。
ベンダー中立の立場
特定ベンダーに依存しない立場から、お客様にとって最適な選択肢を公平に評価します。
コスト比較の支援
クラウドGPU、オンプレGPU、推論APIのTCO(総所有コスト)比較資料の作成を支援します。
関連リソース
Qualiteg Blogで公開しているLLM推論基盤プロビジョニング講座をご覧ください。

NCCL error: unhandled cuda error が出たら ─ WSL2 + マルチGPU + vLLM
WSL2 + RTX 4090×2 + vLLM でNCCL初期化に詰まった事例の原因切り分けと回避策を共有します。

2026年 NVIDIA GPU 一発検索ツール
世代・SMアーキテクチャ別にNVIDIA GPUを横断検索できるツールを公開しています。
LLM学習の現実:GPU選びから学習コストまで徹底解説
LLMの学習に必要なGPU枚数とコストの現実。LLaMA 2やDeepSeek-V3の事例を交えて解説します。

その処理、GPUじゃなくて勝手にCPUで実行されてるかも ~ONNX RuntimeのcuDNN警告と対策~
ONNX RuntimeでGPU推論時の「libcudnn.so.9」エラーの原因と解決方法を解説。

LLM推論基盤プロビジョニング講座 第5回:GPUノード構成から負荷試験までの実践プロセス
GPUノード構成見積もり、負荷試験、トレードオフ検討と実際のサーバー構成例を解説します。

LLM推論基盤プロビジョニング講座 第4回:推論エンジンの選定
vLLM、TGI等の推論エンジンの特徴と選定ポイントを解説します。

LLM推論基盤プロビジョニング講座 第3回:使用モデルの推論時消費メモリ見積もり
GPUメモリ消費の二大要素とモデルフットプリント、KVキャッシュについて解説します。

LLM推論基盤プロビジョニング講座 第2回:LLMサービスのリクエスト数を見積もる
GPUノード数算出のための想定リクエスト数の見積もり方法を解説します。

LLM推論基盤プロビジョニング講座 第1回:基本概念と推論速度
LLM推論基盤構築の基礎となる概念と推論速度の考え方を解説します。

GPUサーバーの最適容量計算:キューイング理論と実践的モデル
キューイング理論を用いたGPUサーバーの最大ユーザーサポート数計算方法を解説します。

2025年 NVIDIA GPU 一発検索ツール
Blackwell、Hopper、Ada Lovelaceなど、NVIDIAのGPUを世代・スペックで絞り込み検索。

【ChatStream】大容量のLLMの推論に必要なGPUサーバー構成
Llama3-70Bを例に、大容量LLM推論に必要なGPUサーバー・クラスター構成を動画で解説。
AIセキュリティ
AIで守り、AIの脅威に備え、AI自体を守る ― 3つの領域を横断で
「AIとセキュリティ」は、もはやひとつの話ではありません。
生成AIとLLMが業務の中核に入り込んだいま、セキュリティの前提そのものが変わりました。 かつての中心が「いかに侵入を防ぐか」だったのに対し、現在は攻撃側も防御側もAIを使い始め、 攻撃は機械の速度で自動化・大規模化しています。ガートナーが AI TRiSM(AI Trust, Risk and Security Management) を 重要トレンドに掲げたように、AIの信頼性・リスク・セキュリティを統合的にマネジメントすることは、 いまや情報システム部門だけでなく経営のアジェンダになりました。
この領域は、大きく3つに整理できます ― ①防御にAIを使う「AIで守る」、 ②攻撃にAIが使われる「AIを使った攻撃から守る」、 ③AIシステム自体が標的になる「AIを守る」。 「誰がAIを使うのか」「何を守るのか」によって、必要な対策も予算もリスクの性質もまったく異なります。 私たちは特に第三の領域(AIを守る)を早くから追い、プロンプトインジェクションやジェイルブレイクといった LLM固有の攻撃と防御を検証する攻防診断プロダクト LLM-Audit を自社開発してきました。 一般論やチェックリストの提示ではなく、御社のAI活用に即して「どこから・何を・どこまで守るか」を一緒に描き、 実装に落とせる現実的なセキュリティを設計します。
AIセキュリティの3つの領域
① AIで守る
- 大量ログ・アラートのAI分析(AI-SOC)
- 脅威の優先順位付け・異常検知
- ガーディアンエージェント(AIがAIを守る)
- 「誰が・どのAIに・何を」の可視化と統制
② AIを使った攻撃から守る
- AI生成フィッシング・偽メール文面
- ディープフェイク音声・画像・なりすまし
- 自動化された偵察・脆弱性探索
- 攻撃の「量・速度・巧妙さ」への備え
③ AIを守る ― 私たちの中核
- プロンプトインジェクション/Jailbreak
- RAGの参照データ汚染・コンテキスト改ざん
- AIエージェントの権限悪用・暴走
- 日本語PII漏洩・「見えないPII」対策
- 自社プロダクト LLM-Audit で診断・防御
いま、企業が備えるべき3つの転換点
3つの領域のうち、いま特に大きく動いているのが ②攻撃側のAI化 と ③AIシステムの保護 です。AIの進化は速く、「起きてから直す」では追いつきません。これから訪れる変化を見据えて、いまから設計しておくべき論点を整理します。
フロンティア級オープンLLMの登場と、長期防衛計画
最強クラスのAIモデルは、長年見つからなかった脆弱性を数分で発見し、偵察から攻撃コードの組み立てまでを自動でこなす水準に近づいています。やがて同等の力を持つオープンウェイトモデル(誰でも入手できるLLM)が登場すれば、その能力は攻撃者の手にも渡り、高度なサイバー攻撃の「参入障壁」が一気に下がります。重要なのは「いつ出るか」を待つことではなく、「出たら何をするか」を先に設計しておくこと。単発の脆弱性診断や場当たりのパッチ対応ではなく、攻撃者と同じAIの視点で自社を継続的に点検するAIレッドチーミングと脅威インテリジェンスを運用に組み込み、発見→検証→優先順位付け→修正→監査を回す長期防衛計画へ移行することが、これからの標準になります。
- 脅威の継続的アップデートを前提とした運用設計
- 単一モデルへのロックイン回避・縮退運転計画
- 「脆弱性が大量に見つかる世界」を回せる運用パイプライン整備
AIエージェント型開発が主流になると、攻撃面が変わる
Claude Code に代表されるAIエージェント型の開発・運用が急速に主流化しています。AIが自律的にコードを書き、コマンドを実行し、外部と通信する――その便利さの裏で、人間が一行ずつ確認していた頃にはなかった新しい攻撃面が生まれます。エージェントに与えた権限が広すぎれば、たった一度の乗っ取りが致命傷になり、AIの出力をそのまま実行・反映すれば、思わぬ破壊や情報漏洩につながります。「何を・どこまでエージェントに任せるか」を設計しないまま導入すると、利便性がそのままリスクに変わります。だからこそ、開発のはじめから運用・監査までを貫いてセキュリティを組み込むセキュアな AI-SDLC の発想が欠かせません。
- 取り込んだコード・Web・Issue 経由の間接プロンプトインジェクション(エージェントの乗っ取り)
- エージェントの権限・実行範囲の設計(最小権限・人間の承認境界)
- AIが生成したコードと依存パッケージのサプライチェーンリスク
- エージェントの自己申告は証拠にならない(ログによる裏取り・監査)
自社でLLMを持つなら、守りも自社で設計する
ローカル/オープンLLMの性能向上で、機密を外に出さず自社内(オンプレ/プライベートクラウド)でLLMを立ち上げる企業が増えています。ただし「オンプレにしたから安全」は誤解です。守るべきはモデルの置き場所ではなくデータの流れ。自社でAIを「持つ」なら、ゼロトラストの原則(誰も信頼せず常に検証)をLLMアクセスに適用し、認証・認可、RAGの権限設計、ファインチューニング済みモデルの重みや推論GPU基盤の保護、学習・推論データへのモデルポイズニング対策、そして必要に応じた機密計算(Confidential Computing)まで――守りをAIガバナンスとして一貫設計する責任を、自社が負うことになります。
LLM-Audit
当社はLLM-AuditというLLMセキュリティ診断プロダクトを開発・提供しています。 このプロダクト開発で培った知見を活かし、お客様のLLMシステムのセキュリティ強化を支援します。
pii-fi(ピーアイファイ)
攻撃を100%防ぎきることはできません。だからこそ重要なのが、「漏れても被害をコントロールできる状態」を先に作っておくことです。 pii-fi は、AIに渡すデータから個人情報(PII)を検出し、徹底的に除去・匿名化しておくプロダクト。 たとえ万が一情報が漏洩しても、そこに守るべきPIIが残っていなければ、漏洩のダメージを大きく抑え込めます。 日本語特有の表記ゆれや資料に潜む「見えないPII」にも対応し、検知・診断の LLM-Audit と組み合わせて多層防御を構成します。
主に対応する脅威・脆弱性
LLM・AIシステムには、従来のソフトウェアにはなかった固有のリスクがあります。敵対的なプロンプトからデータ漏洩、サプライチェーン攻撃まで、私たちが実際の開発・運用で向き合ってきた脅威に、実践的に対応します。
プロンプトインジェクション
- 直接的インジェクション
- 間接的インジェクション
- Jailbreak攻撃
- システムプロンプト漏洩
情報漏洩
- 学習データ抽出
- PII(個人情報)漏洩
- 機密情報の意図しない出力
- コンテキスト漏洩
有害出力
- 有害コンテンツ生成
- バイアス・差別的出力
- 誤情報・ハルシネーション
- 著作権侵害リスク
システム攻撃
- DoS攻撃(リソース枯渇)
- モデル窃取
- APIキー漏洩
- サプライチェーン攻撃
エンタープライズ統合・アクセス基盤
- Active Directory/ID・認証連携
- アクセス制御・権限設計
- プロキシ経由のAI利用統制(DLP)
- 全社AI活用のガバナンス・シャドーAI対策
日本語特有のリスク
- 日本語アラインメント問題(英語では弾く攻撃が日本語で素通り)
- 日本語の曖昧性(「三沢」は人名か地名か)
- ファイルに潜む「見えないPII」(ノート/非表示シート/OCR)
- 作話的プロンプトインジェクション(AIの自己申告を検証)
支援の流れ
課題ヒアリング
お客様のLLMシステムの構成、利用シーン、セキュリティに関する懸念や課題をヒアリング
最新動向のシェア
AIセキュリティの最新攻撃手法、業界動向、ベストプラクティスの情報共有
LLM-Audit導入支援
自社開発のLLM-Auditツールを活用した脆弱性診断の導入・運用支援
Qualitegの強み
プロダクト開発の知見
LLM-Auditの開発を通じて蓄積した、LLMセキュリティに関する深い技術的知見を持っています。
最新攻撃手法の把握
日々発見される新たな攻撃手法をキャッチアップし、診断項目を継続的にアップデートしています。
実践的な対策提案
理論だけでなく、実際にLLMシステムを運用している経験に基づいた、実装可能な対策を提案します。
「作る側」の知見で守る
LLM推論基盤(GPU)の構築・運用やモデル開発まで自社で手がけているからこそ、机上論ではなく実装に即したセキュリティを設計できます。自社LLMを立てる企業の現実的な悩みに伴走します。
動画で見る AIセキュリティ
Qualiteg公式YouTubeでも、AIセキュリティの考え方を解説しています。


関連リソース
Qualiteg BlogでAIセキュリティ(LLM攻防・日本語PII保護・ゼロトラスト/AD連携)に関する技術解説記事を公開しています。

AIが攻撃と防御の両方を変える――セキュリティ市場2026と次の10年
AIとセキュリティを「AIで守る/AIを使った攻撃から守る/AIを守る」の3領域に整理し、今後10年の市場と企業の備えを展望します。

AI は、来なかった攻撃を「検知」し、「拒否」し、「反省」した
プロンプトインジェクション検知の“誤認”(来なかった攻撃の作話)を生ログから検証します。

大企業のAIセキュリティを支える基盤技術 ─ Active Directory【第6回】
AIセキュリティの土台となるActive Directoryの実践的な構成例を解説するシリーズです。

大企業のAIセキュリティを支える基盤技術 - 今こそ理解するActive Directory 第6回 よくある問題と解決方法
設定が完璧なはずなのに「なぜかうまく動かない」という場面は、実際の現場では必ず訪れます。原因はKerberosの失敗、時刻のずれ、SPNの設定ミス、DNS関連の問題など多岐にわたりますが、体系的にトラブルシューティングすることで必ず解決できます。

PII検出の混同行列では見えないもの ― 認識器間衝突と統合テスト
こんにちは!Qualiteg研究部です! 個人情報(PII: Personally Identifiable Information)の自動検出は、テキスト中から特定の表現を抽出し、それがどの種類のPIIに当たるかを判定する問題として捉えることができます...

大企業のAIセキュリティを支える基盤技術 - 今こそ理解するActive Directory 第5回 ブラウザ設定と認証
こんにちは、今回はシリーズ第5回「ブラウザ設定と認証」について解説いたします! さて、前回(第4回)では、プロキシサーバーをドメインに参加させることで、ChatGPTやClaudeへのアクセスを「誰が」行ったかを確実に特定する仕組みを解説し...

企業セキュリティはなぜ複雑になったのか? 〜AD+Proxyの時代から現代のクラウド対応まで〜
ファイアウォール&プロキシ時代からSASE/SSEまでの企業セキュリティ進化の歴史と、LLMセキュリティへの応用を解説します。

大企業のAIセキュリティを支える基盤技術 - Active Directory 第4回 プロキシサーバーと統合Windows認証
ChatGPTやClaudeへのアクセス監視のためのプロキシサーバーとKerberos認証の統合を解説します。

大企業のAIセキュリティを支える基盤技術 - Active Directory 第3回 ドメイン参加
クライアントPCやサーバーをドメインに参加させる手順と、その裏側の仕組みを解説します。

大企業のAIセキュリティを支える基盤技術 - Active Directory 第2回 ドメイン環境の構築
AIセキュリティ検証環境のためのActive Directoryドメイン環境構築手順を詳しく解説します。
ゼロトラスト時代のLLMセキュリティ完全ガイド:ガーディアンエージェントへの進化を見据えて
ゼロトラストとLLMセキュリティ、AIエージェント時代のガーディアンエージェントという3つの変革について解説します。

大企業のAIセキュリティを支える基盤技術 - Active Directory 第1回 基本概念の理解
AIセキュリティソリューションと企業環境を統合するためのActive Directoryの基本概念を解説します。

AIエージェント時代の新たな番人「ガーディアンエージェント」とは?
ガートナーが発表したガーディアンエージェントの概念と、AIエージェント時代に必要となる新たな監視役について解説します。

LLM活用における段階的PIIマスキング
ファイルに潜むPIIの検出方法と、LLM-Audit PII Protectorによる段階的なマスキング処理について解説します。

LLM時代の企業情報防衛:PIIセキュリティの新たな挑戦
生成AI時代に求められるPIIセキュリティの新しい定義と、企業が取るべき情報防衛戦略について解説します。

LLM-Audit ~LLMへの攻撃と防衛の最前線 ~
当社が開発したLLMセキュリティソリューション「LLM-Audit」の機能と、LLM特有の脆弱性への対策を解説します。

【LLMセキュリティ】ハルシネーションの検出方法
RAGにおけるハルシネーション検出モデル「LYNX」の仕組みと、LLMの出力の忠実性を判定する方法を解説します。

【LLMセキュリティ】Llama Guard:AI安全性の第一歩
Meta社が開発したLlama Guardの特徴と、LLMの入出力に対するセーフガード機能について解説します。

【LLMセキュリティ】ゼロリソースブラックボックスでのハルシネーション検出
外部データベースを使用しないゼロリソース状態でのハルシネーション検出手法「SelfCheckGPT」を解説します。
AIアバター・AIヒューマン
音声AI・画像生成を組み合わせたAIキャラクター開発
AIに「顔」と「声」を与える。
LLMの対話能力と、音声認識・音声合成・画像生成技術を組み合わせることで、 より自然で親しみやすいAIインターフェースを実現します。 カスタマーサポート、教育、エンターテインメントなど、様々な領域での活用を支援します。
技術領域
音声認識AI
- Whisper活用
- リアルタイム音声認識
- 話者識別
- ノイズ耐性強化
音声合成AI
- 高品質TTS
- 感情表現・抑揚制御
- Voice Cloning
- 多言語対応
画像生成・アバター
- Stable Diffusion活用
- キャラクター生成
- リップシンク
- 表情・動作制御
統合システム
- 対話×音声×映像の統合
- リアルタイム処理
- 低遅延設計
- マルチプラットフォーム
活用シーン
- 24時間対応のAIカスタマーサポート
- 教育・研修用のAIチューター
- 店舗・施設での案内AIキャラクター
- エンターテインメント向けAIキャラクター
- 社内向けAIアシスタントの顔と声の付与
Qualitegの強み
マルチモーダルの統合力
LLM、音声、画像といった複数のAI技術を組み合わせたシステム開発の実績があります。
リアルタイム処理の知見
音声認識→LLM→音声合成の低遅延パイプライン設計により、自然な対話体験を実現します。
GPU基盤の活用
自社GPU環境を活用し、各種モデルの性能検証や最適な組み合わせの選定を素早く行えます。
関連リソース
Qualiteg Blogで公開しているAIリップシンク技術の解説記事をご覧ください。

AIリップシンクの実現方法 第4回:LSTMの学習と限界、そしてTransformerへ
LSTMモデルの限界と、より高精度なTransformerモデルへの移行について解説します。

AIリップシンクの実現方法 第3回:wav2vec特徴量から口形パラメータへの学習
wav2vecの特徴量から口の形状パラメータを学習するモデル構築について解説します。

AIリップシンクの実現方法 第2回:AIを使ったドリフト補正
音声と映像のズレを自動補正するAIドリフト補正技術について解説します。

AIリップシンクの実現方法 第1回:音素とwav2vec
AIリップシンク技術の基礎となる音素の概念とwav2vecの活用方法を解説します。
自然言語処理/NLP
日本語特化の高度なテキスト処理・PII検出技術
日本語という言語の奥深さに寄り添う。
敬称付き人名、表記ゆれする住所、文脈で意味が変わる金額情報—— 多言語対応のPII検出ツールは、これらの日本語固有の難しさを十分にカバーできていません。 私たちは長年にわたり自然言語処理を専門的に研究してきた専門家チームを擁し、 形態素解析や固有表現認識(NER)といった古典的手法から、 最新のTransformer・LLMまで、用途・精度・スピードに応じた幅広いテクノロジーを保有しています。 独自に構築したオリジナルコーパスと、日本語の文化的背景への深い理解を武器に、 日本語専用のPII検出・マスキングエンジンとして実用化・プロダクト化を実現。 日本企業にとって真に実用的な自然言語処理ソリューションを提供します。
日本語という言語の美しさと複雑さ—そしてQualitegのアプローチ
汎用的な多言語対応ツールが100言語に対応するとき、各言語への投資は必然的に薄くなります。 日本語の複雑さに対応するには、ルールベースのヒューリスティックな手法と、機械学習・深層学習アプローチのバランスの取れた組み合わせが不可欠です。 私たちは日本語処理に特に深い強みを持ち、両方の技術を深く理解した上で課題に応じて最適な手法を選択・統合できることを強みとしています。
世界でも稀な多層的文字体系
ひらがな、カタカナ、漢字、ローマ字、数字。これらが有機的に組み合わさることで豊かな表現力を生み出しています。 一つの企業名でも「株式会社国際情報技術研究所」「KJK研究所」「ケージェーケー研究所」など多様な表記が可能であり、 この柔軟性はコンピューターによる処理を困難にする要因でもあります。
文脈が意味を決定する言語
「三沢から連絡がありました」—これは人名?会社名?地名?日本語では文脈なしには判断できません。 英語なら"Mr. Misawa"(人名)、"Misawa City"(地名)と明確に区別されますが、 日本語では前後の文脈を広く見る必要があります。
敬語システムが提供する情報
「山田が来ました」「山田さんが来ました」「山田様がいらっしゃいました」「山田先生がお見えになりました」— 敬称の種類によって人物の立場や、どの程度のマスキングが必要かを判断できます。 敬語は単なる礼儀ではなく、話者間の関係性、社会的地位など多層的な情報を含んでいます。
技術領域
PII(個人識別情報)検出
- 日本語特化PII検出エンジン
- 敬称駆動型人名検出
- 日本の住所体系への完全対応
- 電話番号・メール等のパターン検出
- 文脈を考慮した高精度検出
固有表現認識(NER)
- 人名・組織名・地名の識別
- 日本語コンテキスト強化器
- 機械学習ベースNER
- Transformerベース深層学習
形態素解析・構文解析
- 各種形態素解析エンジン活用
- カスタム辞書構築
- 品詞情報を活用した文脈判断
- 係り受け解析
- 専門用語・新語への対応
テキストマスキング・非識別化
- 5種類の非識別化方式(置換・マスク・ハッシュ化等)
- LLM活用前の安全なPIIマスキング
- リバーシブル仮名化(復元可能な非識別化)
- DLP・SIEM・LLMワークフローへの組み込み
- 文脈を理解した機密情報の分類と処理
処理レベルと精度・速度のトレードオフ
実際のビジネスシーンでは、用途・目的・セキュリティ基準に応じて速度と精度のバランスを柔軟に調整する必要があります。 私たちは5段階のアプローチで、データの重要度に応じた最適な処理レベルを提案します。
超高速スキャン
数万件/秒以上正規表現による高速パターンマッチング。電話番号、メールアドレス、クレジットカード番号など形式が明確な情報を瞬時に検出。
文脈解析パイプライン
数千件/秒大量ドキュメントから文脈パターンを自動学習し、検出精度を向上。同じ数値でも「年収」と「売上高」を区別するなど、意味レベルの判定を実現。
高精度NER
数百件/秒機械学習による高度な固有表現認識。文全体の構造を考慮した柔軟な判定。
広域文脈理解
100件/秒Transformerベースの深層学習モデルによる文書全体の文脈理解。NERを超え、長距離の依存関係や暗黙的な情報まで推論。
LLM統合モード
数十件/秒大規模言語モデル統合。人間レベルの言語理解で、略語、専門用語、暗黙の参照関係も理解し適切なマスキングを提案。
こんなご相談に対応
- 多言語対応ツールでは日本語のPII検出精度が不十分で、漏れや誤検出が発生している
- LLMに社内データを入力する前に、個人情報を安全にマスキングしたい
- 「年収500万円」と「売上高500万円」を文脈から区別して適切に処理したい
- 契約書や議事録から特定の情報を自動抽出・マスキングしたい
- 既存のDLP・SIEM・LLMワークフローにPII検出を組み込みたい
- 社内文書から人名・組織名・製品名を正確に抽出したい
- 敬称付き人名(「山田部長」「田中様」等)や日本特有の住所表記にも対応したPII検出が必要
ご提供できる知見(一例)
日本語の自然言語処理技術について深い知見を持ち、実際にPII検出・マスキングプロダクトを開発・運用している経験から、 以下のような専門的な知見をお伝えできます。これらは一例であり、お客様の課題に応じて幅広くご支援可能です。
日本語特化の検出ロジック
敬称駆動型検出(「様」「さん」を手がかりにした人名特定)、階層的パターンマッチングによる住所検出など、日本語の文化的特性を活かした検出技術を解説します。
多層的フィルタリング技術
形態的フィルタリング、統計的フィルタリング(姓名データベース照合)、文脈的フィルタリング、除外リスト適用など、複合的なアプローチで精度を高める手法をご紹介します。
最適化技術の適用
量子化によるモデルサイズ削減、動的バッチングによるGPU利用効率向上、知識蒸留による軽量モデル作成など、「高精度だが軽量」を実現する技術をお伝えします。
Qualitegの強み
長年の研究と専門家チーム
自然言語処理を専門的に研究してきた専門家チームが在籍。形態素解析やNERから最新のTransformer/LLMまで、技術の変遷を熟知した上で最適解を提案します。
オリジナルコーパスと実用化実績
独自に構築した日本語コーパスを保有し、PII検出エンジンとして実用化・プロダクト化を達成。理論だけでなく、本番環境で動作する実装力があります。
ヒューリスティック×機械学習の融合
日本語の複雑さにはルールベースの緻密な対応と、深層学習による汎化能力の両方が必要。両技術を深く理解し、課題に応じて最適に組み合わせます。
フルスタックな技術対応力
形態素解析や固有表現認識(NER)からTransformer/LLMまで。用途・精度・スピード要件に応じた幅広い技術を提供できます。
日本語処理に特に深い強み
多言語対応の汎用ツールでは対応しきれない、日本語の敬称体系、漢字の多義性、住所の階層構造、電話番号の多様性など、日本語固有の課題ひとつひとつに専用の検出ロジックを組んでいます。
柔軟なレベル設計
用途・予算・セキュリティ要件に応じて、5段階の処理レベルから最適なアプローチを提案。過剰な精度追求によるコスト増を防ぎます。
LLM-Audit
「LLM-Audit」は、企業のLLM活用を包括的に監査するセキュリティソリューションです。 社員からLLMへの送信(アウトバウンド)と、LLMからの応答(インバウンド)の双方向監査を実現。 プロンプトインジェクション対策、ジェイルブレイク攻撃防御、有害コンテンツの検出・ブロックなど、 企業のAI活用におけるセキュリティとコンプライアンスを強化します。
PII-Fi™ API
「PII-Fi™ API」は、当社が長年培ってきた日本語NLP技術を凝縮した、日本語専用のPII検出・マスキングクラウドAPIです。 敬称付き人名、表記ゆれする住所、文脈依存の機密情報まで高精度に検出。 5種類の非識別化方式とリバーシブル仮名化に対応し、APIひとつで既存のDLP・SIEM・LLMワークフローに組み込めます。 このPII検出エンジンの実用化・プロダクト化の実績が、私たちの日本語NLP技術力の証明です。
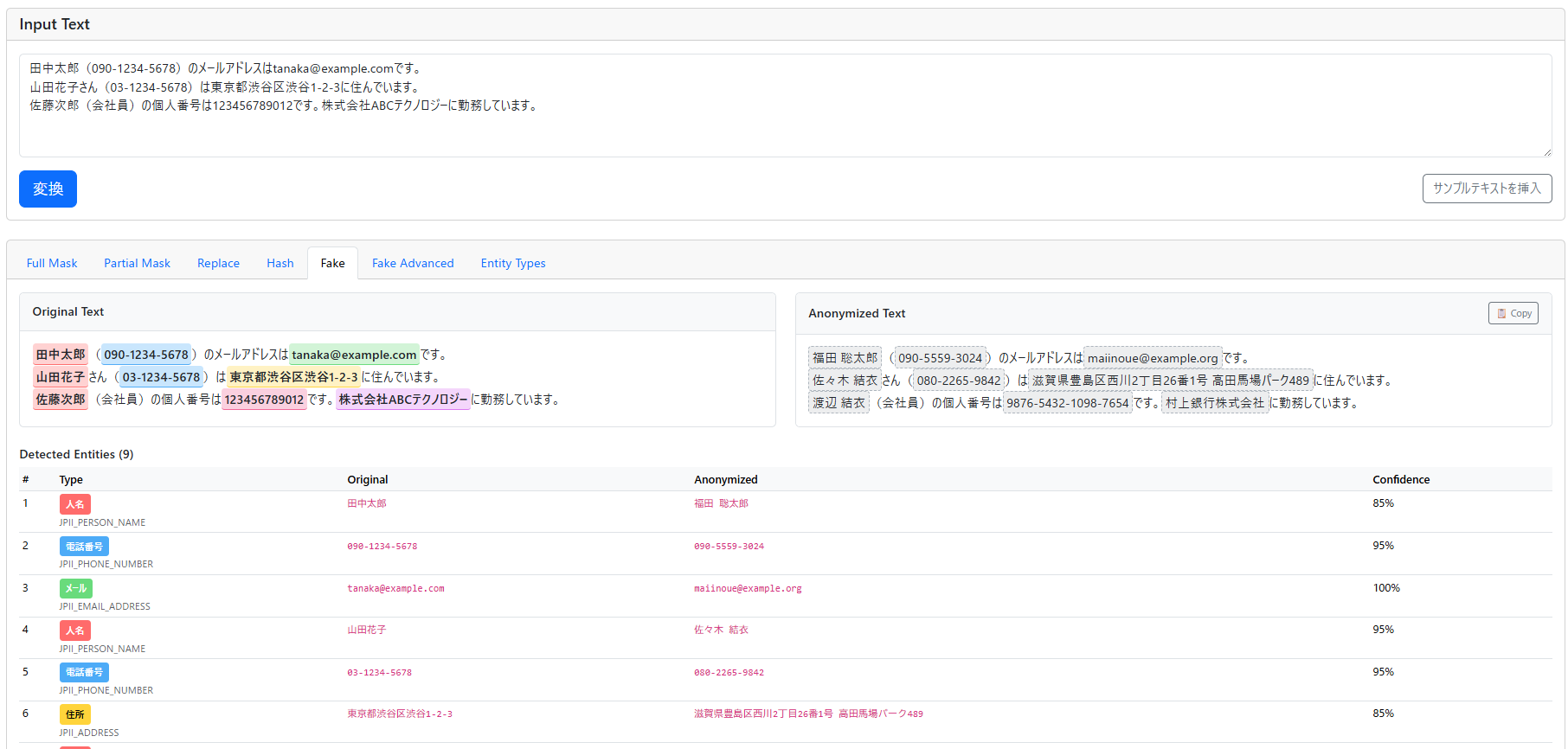
関連リソース

個人情報検出の精度を、どう正しく語るか ― Recall・信頼区間・代表性
PII検出の精度を誠実に評価・報告するための、統計的な評価設計の考え方を解説します。
PII検出の混同行列では見えないもの ― 認識器間衝突と統合テスト
個人情報(PII)の自動検出における認識器間衝突の問題と、それを検出するための統合テスト設計について解説します。

PIIの高精度検出を支える技術~日本語という言語の奥深さに寄り添う~
グローバルツールと日本語特化ツールの共存。日本語の独特な文字体系と文化的背景に深く寄り添い、日本企業に実用的なPII検出ソリューションを提供します。
AIによるソフトウェア開発の変革支援
開発ライフサイクル全体へAIを統合し、生産性と品質を向上
開発プロセス全体にAIを統合し、持続可能な生産性向上を実現。
ソフトウェア開発は今、構造的な危機に直面しています。技術的負債の対処に開発時間の23〜42%が浪費され、 37%のプロジェクトが要件の曖昧さで失敗し、87%のCTOが技術的負債をイノベーションの最大の障害と認識しています。 本サービスでは、AIを開発ライフサイクル全体に統合し、「点」の効率化ではなく「面」での変革を支援します。
ソフトウェア開発が直面する構造的課題
ソフトウェア開発市場は2025年に5,700億ドル規模、2030年には1兆ドル超へ成長が予測されています。 しかし、この急成長の裏で、開発現場は深刻な課題に直面しています。
よくある課題パターン
技術的負債の蓄積
- 新機能開発より既存コードの修正に時間を取られる
- 「とりあえず動く」コードの積み重ねが将来の足かせに
- リファクタリングが常に後回し
- 100万行で年間30.6万ドルのコスト
要件の曖昧さと手戻り
- 開発後半で「要件と違う」と指摘される
- テストフェーズで大量の不具合が発覚
- ステークホルダー間で認識が食い違う
- 後工程での修正コストは10〜100倍
ドキュメント不足と属人化
- 「コードはあるが仕様書がない」
- 特定エンジニアしか触れないコード
- 新メンバーの立ち上がりに数ヶ月
- 国際分業における共通言語の欠如
変更の影響範囲が見えない
- 小さな修正でも全体テストが必要
- 誰も触りたがらないレガシーコード
- リリースのたびに長いテスト期間
- 影響分析に開発時間の15〜25%消費
AI統合による解決アプローチ
従来のAI活用は、コード補完など特定タスクの効率化にとどまっていました。 しかし、真の変革を実現するには、AIを開発ライフサイクル全体に統合する必要があります。
従来のアプローチ
- 特定タスクの自動化
- 人間がすべてを主導
- ツールごとに分断
- 10〜20%の効率化
変革後のアプローチ
- ライフサイクル全体への統合
- AIと人間の協働
- データ・コンテキストの連携
- 30〜50%以上の生産性向上
段階的な成熟度モデル
一足飛びの変革はリスクが高いため、段階的に進めます。
AI-Assisted(AIによる支援)
コード補完、ドキュメント生成など個別タスクの効率化。開発者が主導、AIがサポート。
AI-Augmented(AIによる拡張)
複数フェーズにまたがるAI活用。AIが提案、人間が判断・承認。
AI-Driven(AIによる駆動)
ライフサイクル全体をAIが支援。AIがドラフト作成・実行、人間が監督・品質保証。
開発ライフサイクル各フェーズでのAI活用
ソフトウェア開発の各フェーズには、それぞれ固有の課題があります。AIを適切に活用することで、 これらの課題を解決し、プロジェクト全体の成功率を高めることができます。 以下に、各フェーズでの具体的なAI活用方法をご紹介します。
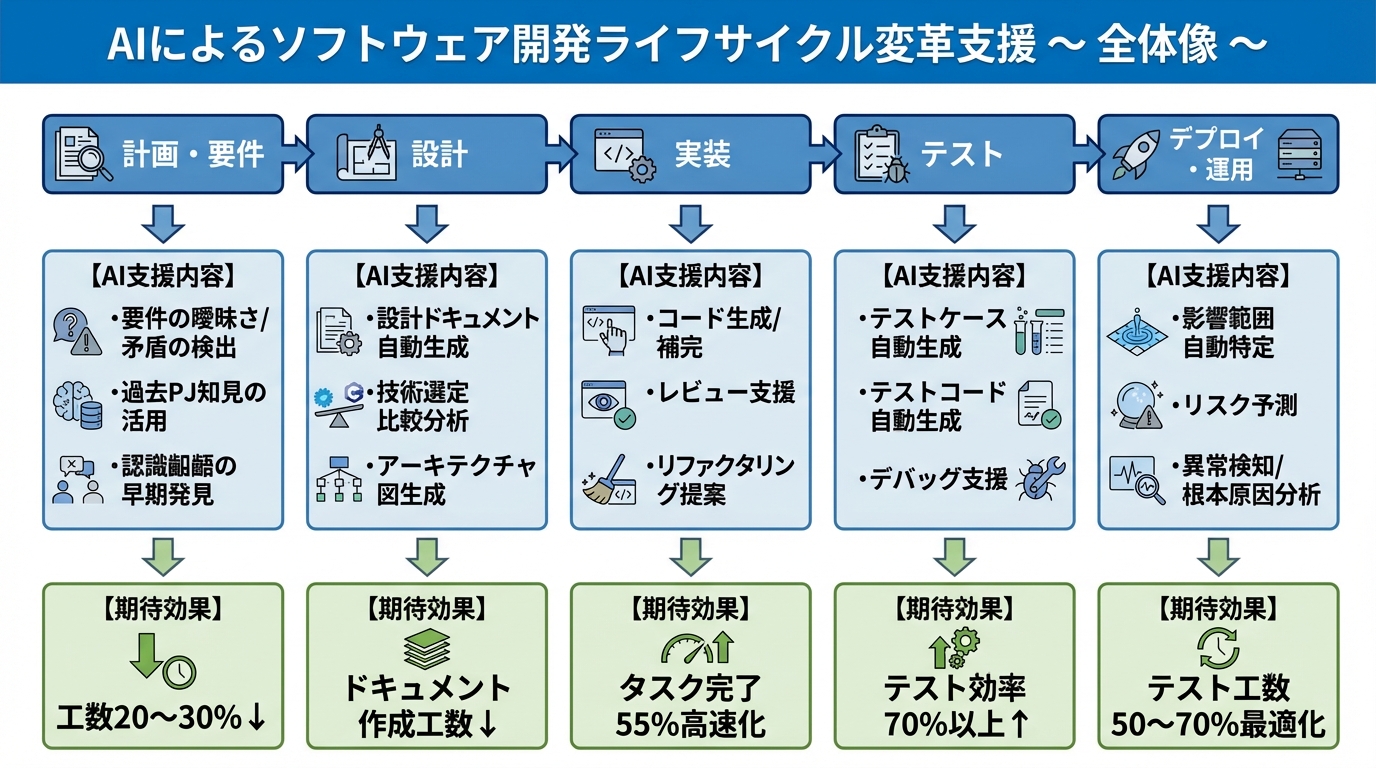
計画・要件フェーズ
プロジェクトの成否を左右する要件定義フェーズ。ここでの曖昧さや見落としが、 後工程での手戻りや予算超過の原因となります。AIを活用することで、 人間が見落としがちな矛盾や曖昧さを早期に発見し、プロジェクトの土台を強固にします。
設計・アーキテクチャフェーズ
システムの骨格を決める設計フェーズでは、技術選定やアーキテクチャ設計の判断が求められます。 ドキュメント作成に多大な時間がかかり、また経験豊富なアーキテクトの知見が属人化しがちです。 AIを活用することで、設計作業の効率化とナレッジの共有を実現します。
実装・コーディングフェーズ
開発者が最も多くの時間を費やすコーディングフェーズ。AIコーディングアシスタントの導入が最も進んでいる領域ですが、 単なるコード補完にとどまらず、レビュー支援やリファクタリング提案まで活用範囲を広げることで、 より大きな効果を得られます。
テスト・品質保証フェーズ
品質を担保するテストフェーズは、しばしばボトルネックになります。テストケースの設計、 テストコードの実装、デバッグなど、多くの工数がかかる作業をAIが支援することで、 品質を落とさずにテスト工程を効率化できます。
デプロイ・運用フェーズ
本番環境へのリリースと、その後の安定運用を担うフェーズ。「この変更は本当に安全か?」 という不安を解消し、障害発生時の迅速な対応を実現するために、AIが強力な支援を提供します。
具体的ユースケース
AI活用の効果を具体的にイメージしていただくために、よくある課題と、それをAIがどのように解決できるかをご紹介します。 これらは実際にお客様からご相談いただくことの多いシナリオです。
レガシーコードの可視化とドキュメント自動生成
「このシステム、作った人がもう退職していて、誰も全体像を把握していない」「新しく参画したベンダーにシステムを説明するのに1ヶ月かかった」「オフショアチームがコードを読み解くだけで数週間かかっている」——長年運用されてきたシステムほど、このような問題を抱えがちです。ドキュメントは古くて実態と合っておらず、コードを読める人も限られている。新機能追加や保守のたびに、膨大な時間が「理解するため」だけに費やされています。
当社のAIエージェントがコードベース全体を解析し、モジュール構成・処理フロー・データの流れを整理したドキュメントを作成します。「このクラスは何をしているのか」「この関数の役割は」といった説明を体系的にまとめ、新規参画者向けの「システム概要説明書」や、保守担当者向けの「モジュール別リファレンス」を短期間で整備。属人化していた知識を、誰でもアクセスできる形式知に変換します。
要件とテストの紐付け(トレーサビリティ)の自動化
「この機能のテストケースって、どこに書いてあるんだっけ?」「要件が変更になったけど、どのテストを修正すればいいか分からない」「テストは通っているけど、本当にこの要件をカバーできているのか自信がない」——要件定義書とテストケースが別々に管理され、両者の対応関係が曖昧になっている。その結果、要件変更時の影響範囲が見えず、テスト漏れのリスクを抱えたままリリースを迎えてしまう。
当社のAIエージェントが要件定義書とテストケースの対応関係を整理したトレーサビリティマトリクスを作成します。「この要件はどのテストでカバーされているか」「テストが不足している要件はどれか」を一覧化し、カバレッジを可視化。不足箇所には追加すべきテスト観点も提案します。「なんとなくテストしている」状態から、根拠のある品質保証体制への移行を支援します。
技術的負債の「見える化」と経営層への説明
「なぜ新機能の開発がこんなに遅いのか」と経営層から詰められる。「リファクタリングをしたい」と言っても「それで売上が上がるのか」と予算が取れない。技術的負債が溜まっていることは開発チームは分かっているが、それをビジネス側に説明する言葉を持っていない。結果として負債は放置され、開発速度はますます低下するという悪循環に陥っている。
当社のAIエージェントがコードベースを分析し、技術的負債の現状レポートを作成します。重複コード、複雑度の高い関数、古いライブラリへの依存などを洗い出し、改善優先度を整理。「このまま放置すると工数が増え続けます」「この改善で開発速度○%向上」といったビジネスインパクトに翻訳した経営層向け報告書も作成。リファクタリング予算の確保を支援します。
コード変更の影響範囲を自動で特定
「たった1行変えただけなのに、念のため全体テストが必要と言われた」「このコードは触ると何が起きるか分からないから、誰も手を出したがらない」「リリースのたびに2週間のテスト期間が必要で、リリースサイクルが長くなっている」——変更の影響範囲が見えないために、必要以上に慎重になり、開発のスピードが落ちている。あるいは、影響範囲を見誤って本番障害を起こしてしまった経験がある。
当社のAIエージェントがコードベースの依存関係を解析し、モジュール間の呼び出し関係を整理したドキュメントを作成します。「この関数を変更すると、どこに影響があるか」「確認すべきテストはどれか」を変更前に把握可能に。ベテランの頭の中にしかなかった暗黙知を、チーム全員が参照できる形式知に変換。根拠に基づいた効率的なテスト計画を立てられるようになります。
コードレビューの効率化と品質の標準化
プルリクエストを出しても、レビュアーが忙しくてなかなかレビューされない。レビューが滞留してマージが遅れ、開発のリズムが崩れる。また、レビュアーによって指摘の質やポイントにばらつきがある。あるベテランは細かいところまで見てくれるが、別の人は表面的なチェックで終わってしまう。セキュリティ脆弱性を見落としてリリースしてしまったこともある。
当社のAIエージェントによるレビュー支援を導入します。プルリクエストが作成されると、AIが一次レビューを実施し、潜在的なバグ、セキュリティ上の懸念、コーディング規約との不一致などを自動で検出。人間のレビュアーは設計判断やビジネスロジックの妥当性など、人間でなければ判断できない部分に集中できます。レビュー品質を標準化しながら、待ち時間も短縮。
導入アプローチ
AIを開発プロセスに導入する際、一気に全面展開しようとすると、現場の混乱や期待はずれの結果を招きがちです。 当社では、段階的なアプローチを推奨しています。まず現状を正確に把握し、小さな成功体験を積み重ねながら、 徐々に適用範囲を広げていく。このやり方が、最終的には最も確実に成果につながります。
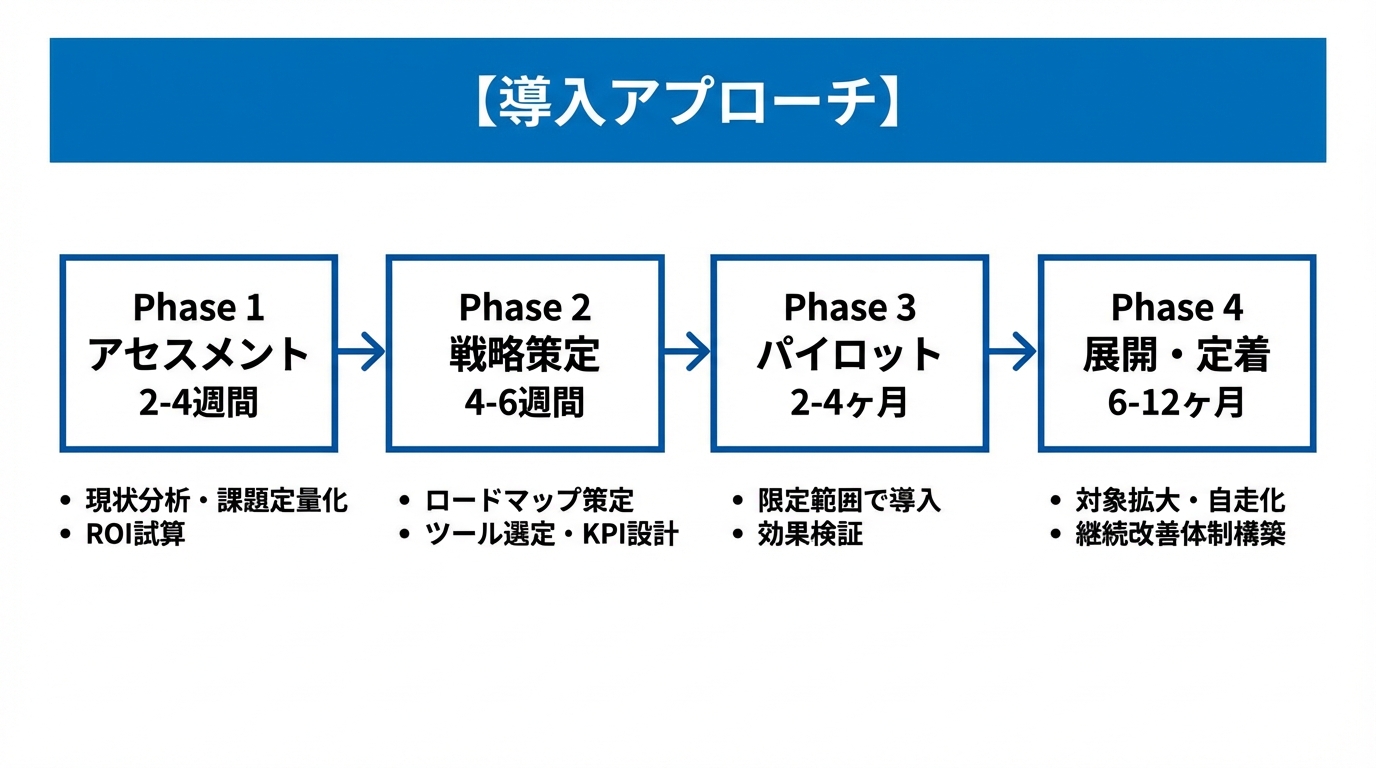
アセスメント
2-4週間現状分析、課題の定量化、優先順位付け
戦略策定
4-6週間ターゲット設計、ツール選定、ロードマップ作成
パイロット導入
2-4ヶ月限定範囲でのAI導入、効果検証
展開・定着
6-12ヶ月対象拡大、プロセス定着、継続改善
期待効果(業界調査に基づく)
定性的効果
- エンジニアの創造的業務へのシフト:単調な作業からの解放
- 属人化の解消:ナレッジの組織資産化
- 開発者体験の向上:技術的負債に埋もれない健全な開発環境
- 採用競争力の向上:最先端の開発環境をアピール
なぜQualitegか
大規模開発・国際協業の実務経験
Qualitegのメンバーは、大規模エンタープライズシステム開発や、海外チームとの国際協業プロジェクトに長年従事してきました。数十人〜数百人規模の開発体制、複数拠点にまたがるチーム編成、異なるタイムゾーンでの協調開発——こうした複雑なプロジェクトを数多く経験しているからこそ、AI導入が現場にもたらす影響を正確に見積もり、実現可能な変革計画を設計できます。
AIエージェントを実際に使い倒している
GitHub Copilot、Cursor、Claude Code、Devin、各種コード生成AIエージェントを日々の商用ソフトウェア開発で先行的・積極的に導入し、実際にプロダクションコードを書いています。どのツールがどの場面で有効か、どこに落とし穴があるか、どう運用すれば定着するか——机上の知識ではなく、自らの実践から得た生きた知見を提供します。
製造業・システム開発現場での実践知見
特に製造業の組込みソフトウェア開発や、業務システム開発の現場での実践経験が豊富です。品質要求が厳しい製造業特有の開発プロセス、レガシーシステムとの統合が必要なエンタープライズ環境——こうした現場でAIをどう活用するか、どこに注意が必要か、具体的なノウハウを蓄積しています。「AIを入れれば解決する」という安易な提案ではなく、現場の制約を踏まえた現実的な導入計画をご提案します。
AI×高品質ソフトウェア開発の両立
AIが生成するコードは便利ですが、品質管理なしに使えばセキュリティホールや保守困難なコードを量産するリスクがあります。Qualitegは、AI活用による開発効率化と、高品質なソフトウェアの両立を追求してきました。AI生成コードのレビュー体制、テスト自動化との連携、技術的負債を増やさない運用ルール——効率だけでなく品質を守る仕組みづくりまで、一貫してご支援します。
成功のためのポイント
技術面
- 段階的導入:一気に全面展開せず、小さく始めて学習する
- ツール統合:分断されたツール群を連携させ、データ・コンテキストを流通
- 品質ゲート:AI出力の検証プロセスを必ず組み込む
- セキュリティ考慮:AI生成コードのセキュリティレビューを徹底
組織面
- 経営層のコミットメント:変革には投資と時間が必要
- 現場の巻き込み:トップダウンとボトムアップの両輪
- 役割の再定義:AIとの協働における人間の役割を明確化
- スキルシフト支援:エンジニアの役割変化に対応した育成
運用面
- 効果測定の継続:KPIを定期的にモニタリング
- フィードバックループ:現場の声を反映した改善
- ナレッジの蓄積:成功・失敗パターンの組織学習
当社のAIソフトウェア開発への取り組み
日々の開発でAIコーディングツールを活用しています
当社では、自社プロダクトの開発において、Claude Code、Cursor、Windsurf、Aider、Clineなど、さまざまなAIコーディングツールを日常的に活用しています。自社開発のツールも含め、複数のツールを目的に応じて使い分けながら、実際のソフトウェア開発を進めています。
こうした実践の中で、各ツールの得意なこと・苦手なこと、そして現時点での技術的な制約についても、肌感覚として理解が深まってきました。
技術的な課題にも向き合っています
AIコーディングツールには大きな可能性がある一方で、実務で使い込むと見えてくる課題もあります。
- 長いセッションでコンテキストが溢れてしまう問題
- セッション間で文脈が引き継がれない問題
- ベンチマークの性能と実際のコードベースでの性能のギャップ
当社ではこうした構造的な課題を技術ブログで分析・公開しており、「どう付き合えば実務で活かせるか」という観点で知見を蓄積しています。
ソフトウェア開発の変遷を見てきた経験があります
当社には、35年以上にわたりソフトウェア開発に携わってきたメンバーがいます。SOA、マイクロサービス、クラウドなど、これまでのさまざまな技術トレンドの中で、何がうまくいき、何がうまくいかなかったかを現場で経験してきました。
その視点から見ても、今回のAIによる開発支援の進化は、実際に動くものが次々と生まれているという点で、過去の変革とは質的に異なるものだと感じています。
等身大の知見をお伝えできます
私たちは、AIツールの可能性を過大評価することも、過小評価することもしたくないと考えています。
「ここまではできる、ここからは難しい」「このツールはこの用途に向いている」「この課題にはこう対処している」——そうした等身大の知見を、コンサルティングを通じてお伝えできればと思っています。
関連リソース
Qualiteg BlogでAIを活用したソフトウェア開発に関する記事を公開しています。
コーディングエージェントの現状と未来 【第3回】“書くAI”から“指揮するAI”へ
複数エージェントを使った開発ワークフローへの進化と、2026年の開発現場の変化を整理します。

PyCharmでIDEがサイレントクラッシュした事例と原因切り分け
再現条件の特定から原因の切り分けまで、実際のトラブルシュートの進め方を共有します。
コーディングエージェントの現状と未来への展望 【第2回】主要ツール比較と構造的課題
主要ツールの詳細比較と、コンテキストウィンドウ制限やセッション間メモリ喪失などの構造的課題を解説します。

今からはじめるClaude Code
話題のAIコーディングエージェント「Claude Code」の導入方法と、Windows環境での運用の考え方を整理します。
AIコーディングエージェント20選!現状と未来への展望 【第1回】全体像と基礎
20種類以上のAIコーディングツールを一挙紹介。商用からオープンソースまで、現場視点で徹底比較します。

エンジニアリングは「趣味」になってしまうのか
vibe codingとエンジニアの将来について。AIが自動的にソフトウェアを作る時代、私たちの役割はどう変わるのか。

使い捨てソフトウェア時代の幕開け ― 市場構造の根本的変革と日本企業
AIエージェントの活用で、1000人月規模のSaaSが2-3名で数週間に。開発生産性の劇的な向上を考察します。
AIエージェント時代の新たな番人「ガーディアンエージェント」とは?
ガートナーが発表した「ガーディアンエージェント」について解説。なぜ今、AIの「監視役」が必要なのか。

AGI時代に向けたプログラマーの未来:役割変化とキャリア戦略
LLM技術の飛躍的進歩でプログラミング業界は大きな転換期に。AGI時代のプログラマーの役割変化を考察します。
参考データ・出典
Claude Code 活用支援
組み込みから大規模開発まで知り尽くした私たちが、本気で“エージェントファースト”に振り切った実戦知見
Claude Code を“なんとなく便利”で終わらせない。チームの再現可能な開発力へ。
組み込みソフトウェアから大規模エンタープライズアプリケーションまで、あらゆる規模の開発プロセスを知り尽くした私たちが、本気でエージェントファーストなコーディングに振り切りました。 Claude Code をはじめとするAIコーディングエージェントを商用開発に実戦投入し、何が効いて、どこにハマるのかを体系化しています。 ツールの小手先の使い方ではなく、開発プロセスそのものをエージェントファーストへ作り変える——その知見を、御社のチームにそのまま移植します。
アドバイザリー領域
コンテキスト & メモリ設計
- CLAUDE.md・コンテキスト設計
- “腐り”始める兆候と対処(context rot)
- 1Mコンテキストを“使い切らない”運用
- メモリ・要約戦略
セッション横断の開発
- 1セッションで終わらないタスクの引き継ぎ
- 状態・文脈の持ち越し設計
- セッション間メモリ喪失への対処
- ハンドオーバ文書の運用
Git・変更管理の規律
- ブランチの切り方・命名規約
- commit メッセージの作法
- merge ルール・レビュー運用
- エージェントが量産するブランチの整理
品質保証・安全設定
- ブラウザE2Eでの自動検証
- AI生成コードのレビュー体制・品質ゲート
- プロンプトインジェクション対策
- 権限(bypass)モード・hook 設定
マルチエージェント・並列実行
- 窓口+サブエージェントの役割分担
- 並列タスクの制御
- Worker をタスク単位で spawn する設計
- オーケストレーション
運用・コスト・人材
- rate limit・LLMコストの監視
- 暴走・ゾンビプロセスの検知
- 定型作業のレシピ化
- AIを“監督”する人材育成
こんなご相談に対応
- Claude Code を導入したが、人によって使い方も成果もバラバラで、チームとして標準化したい
- CLAUDE.md・コンテキスト・メモリの設計指針が欲しい。1Mコンテキストを“使い切らない”運用を確立したい
- 長い作業でコンテキストが“腐り”、精度が落ちる。分割・要約・セッション設計を整えたい
- 1セッションで終わらない開発の引き継ぎ方(ハンドオーバ)を確立したい
- AIが書いたコードのレビューと品質保証、ブラウザE2Eまでの仕組みを作りたい
- プロンプトインジェクション・権限(bypass)・hook など、安全な設定を整えたい
- 「The model's tool call could not be parsed」「Usage Policy違反」など実務で出る不具合の原因と回避策を知りたい
- 開発チーム向けに、エージェントファースト開発のベストプラクティス研修を実施したい
ご提供できる知見(一例)
私たちは自社の開発をエージェントファーストに組み替え、Claude Code を日々の商用開発で使い倒しています。発生した不具合は一次情報(CLIが記録するjsonl)まで降りて解析し、技術ブログで公開してきました。 その実地から、以下のような知見をお伝えできます。これらは一例であり、お客様の課題に応じて幅広くご支援可能です。
コンテキストを“腐らせない”運用
最新モデルは1Mトークンのコンテキストを持ちますが、容量があるからと100%使い切れば、かえって精度が落ちます。“腐り”始める前提で、いつ・どう分割し、何を要約し、何をメモリへ逃がすか。実運用で破綻しないコンテキスト設計をお伝えします。
セッション横断の開発規律
セッション間でメモリが失われる前提で、タスクをどう引き継ぐか。ハンドオーバ文書、状態の持ち越し、ブランチ/commit/merge の作法、エージェントが量産するブランチの整理まで、チームで回る規律を設計します。
実務で出る不具合の原因と回避
「tool call could not be parsed」(特定モデル+extended thinking のストリーミング起因)、「Usage Policy違反」の誤検知、Stream idle timeout など、現場で頻発する不具合を jsonl から原因特定し、回避策を整理しています。
エージェント前提の品質・安全
ブラウザE2Eでの自動検証、AI生成コードのレビュー体制と品質ゲート、プロンプトインジェクション(“来なかった攻撃”を検知したと誤認する事象を含む)への向き合い方、権限(bypass)・hook の安全な設定までご支援します。
マルチエージェント・並列実行の設計
窓口エージェントとサブエージェントの役割分担、並列タスクの制御、Worker をタスク単位で spawn する設計の勘所。複数エージェントを破綻なくオーケストレーションするための実践パターンをお伝えします。
CLI版・Web版・Windows版の使い分け
Claude Code の CLI版・Web版それぞれの得手不得手、Windows 特有の落とし穴(PATH 追加漏れで「claude is not recognized」になる等)まで踏まえ、用途とチーム環境に合った使い分けをご提案します。
暴走・コスト(rate limit)対策
ゾンビプロセスや想定外のループによる“裏で延々とLLMを呼び続ける”無制限な課金を、LLM I/O 監視で検知・遮断。レート制限への当たり方も含め、コストが暴走しない運用設計をご支援します。
クラッシュ・作業消失への備え
Claude Code のクラッシュで、数時間分の調査・議論・決定がまるごと消える事故が起こり得ます。セッション記録の永続化(履歴+索引)で、次のエージェントが前回の状況を完全に引き継げる仕組みを設計します。
AIを正しく“監督”できる人材の育成
AIが書いたものを一行ずつ検算するのではなく、設計・権限・レビューの観点で“監督”する力が要ります。「AIは自信を持って間違える」を前提に、どこまで任せ、どこで止めるかの勘所を持った人材を育成します。
定型作業の“レシピ化”
毎回使うのに忘れがちな手順を“レシピ”として明文化し、誰がやっても同じ品質で再現できるようにします。チームの暗黙知を手順書として資産化し、エージェント運用の再現性を高めます。
CLAUDE.md/指示の肥大化対策
指示は膨らむほど精度がかえって落ちます。コアと参照の分離、内部分割、「必要なときだけ読む」構造化で、CLAUDE.md を太らせずに効かせる設計をお伝えします。
よくあるハマりどころ(一例)
- 長いセッションでコンテキストが溢れ、精度が落ちる(1Mでも100%は使い切らない)
- セッション間で文脈が引き継がれず、毎回ゼロから調べ直しになる
- ベンチマークの数字と、実際のコードベースでの性能のギャップ
- 「The model's tool call could not be parsed」(モデル+extended thinking のストリーミング起因)
- 正規の運用作業が「Usage Policy違反」として誤検知され、作業が止まる
- Windows で「claude is not recognized」になる(PATH 追加漏れ)
- Stream idle timeout が頻発する
- 会話から画像が外れる(an image could not be processed)
- エージェントが作るブランチが溜まって邪魔になる
- ゾンビ Worker が裏で LLM を呼び続け、課金を食いつぶす
- プロンプトインジェクションの“誤検知”(来なかった攻撃を検知したと作話する)
- CLAUDE.md が肥大化して、かえって指示が効かなくなる
——こうした“ハマりどころ”を、私たちは実地で潰してきました。
ご提供する価値
開発プロセスを知り尽くした視点
組み込みから大規模エンタープライズまで、数十年にわたり開発の最前線に立ってきた経験から、流行りの手法ではなく開発プロセスの本質に立ってご支援します。
自分たちで実戦投入した一次知見
Claude Code を商用開発で使い倒し、いまもプロダクションコードを書き続け、不具合は jsonl まで降りて解析・公開しています。机上の知識ではない、生きた知見をお渡しします。
過度な期待の是正と現実的な設計
「AIを入れれば速くなる」という安易な話はしません。効くやり方と避けるべき落とし穴を、確かな根拠とともに整理し、現実的で踏み込んだ変革をご提案します。
関連リソース
Qualiteg Blog で Claude Code・コーディングエージェントの実戦知見を継続的に公開しています。
AI は、来なかった攻撃を「検知」し、「拒否」し、「反省」した
生ログでたどる、AIによる“作話”の記録。プロンプトインジェクション検知の誤認をめぐる考察です。

正規の運用作業が「Usage Policy違反」になる理由 ── 誤検知と対処法
リアルタイム・サイバーセーフガードの誤検知が起きる仕組みと、現場での回避策を解説します。

「The model's tool call could not be parsed」が頻発する問題の原因分析と対策
実際のセッションログ(jsonl)を解析して特定した、ストリーミング起因の不具合の原因と対処法を共有します。
コーディングエージェントの現状と未来 【第3回】“書くAI”から“指揮するAI”へ
複数エージェントを使った開発ワークフローへの進化と、2026年の開発現場で起きている変化を整理します。

Claude Opus 4.7 完全ガイド ── モデル仕様とClaude Codeでの実践ノウハウ
effort設定やツール呼び出しの変化など、Claude Code CLI/Web版での使いこなしを実践的にまとめます。

今からはじめるClaude Code
CLI版・Web版の導入から基本の使い方まで、これから始める方向けにまとめた入門ガイドです。